

Graf veritabanları, geleneksel veritabanlarından farklı olarak, tablolar yerine düğümler, kenarlar ve özellikler kullanan güçlü veri depolama sistemleridir. Biz veri uzmanları, özellikle yüksek düzeyde bağlantılı verileri işlemek gerektiğinde graf veritabanlarının ne kadar değerli olduğunu biliyoruz.
Graf veritabanı nedir? Temelde, karmaşık ilişkileri modellemek için tasarlanmış özel bir veritabanı türüdür. Bu veritabanları, sosyal ağlardan öneri sistemlerine ve dolandırıcılık tespitine kadar birçok alanda kullanılmaktadır. Özellikle dikkat çekici olan, ilişkilerin hacmi ve derinliği arttıkça graf veritabanlarının performansının önemli ölçüde artmasıdır – bu, ilişkisel veritabanlarının genellikle zorlandığı bir durumdur. Graf veritabanlarını anlamak için Neo4j gibi örnekleri inceleyeceğiz ve bu veritabanlarının nasıl çalıştığını detaylı olarak açıklayacağız.
Bu rehberde, ilişkisel veritabanlarının karşılaştığı çok-çoklu ilişki sorunlarını graf veritabanlarının nasıl etkili bir şekilde çözdüğünü göreceğiz. Ayrıca, finansal işlemleri neredeyse gerçek zamanlı olarak işleyebilme ve ilişki örüntüleri aracılığıyla karmaşık dolandırıcılık tespiti yapabilme yeteneklerini de inceleyeceğiz. Graf veritabanlarının temel bileşenlerinden başlayarak, bu güçlü araçların iş dünyasındaki pratik uygulamalarına kadar uzanan kapsamlı bir yolculuğa çıkacağız.
Graf Veritabanı Nedir ve Neden Önemlidir?
Veri dünyasında devrim yaratan graf veritabanları, geleneksel veri depolama yöntemlerinden tamamen farklı bir yaklaşım sunar. Graf veritabanı, veriler arasındaki ilişkileri ön planda tutan, CRUD (Oluşturma, Okuma, Güncelleme ve Silme) işlemlerini graf veri modeli üzerinde gerçekleştiren çevrimiçi bir veritabanı yönetim sistemidir. Bu yapı, düğümler (nodes), kenarlar (edges) ve özellikler (properties) kullanarak verileri ve aralarındaki ilişkileri modellemektedir.
İlişkisel Veritabanlarından Farkı
İlişkisel veritabanları adlarına rağmen ilişkileri ele almakta ironik şekilde yetersiz kalır. Bu veritabanları, verileri saklamak için satır ve sütunlardan oluşan katı şemalı tablolar kullanır. Veriler arasındaki bağlantılar ise yabancı anahtarlar ve JOIN işlemleri aracılığıyla sağlanır. Ancak bu yapı, karmaşık ilişkilerde ciddi performans sorunları yaratır.
İlişkisel veritabanlarında:
- Veri tabloları katı şemalara dayanır ve yeni ilişki türlerini eklemek zordur
- İlişkiler yabancı anahtarlarla temsil edilir, birinci sınıf varlıklar değildir
- Sorgulamalarda birleştirme (JOIN) sayısı arttıkça performans önemli ölçüde düşer
- Veri boyutu büyüdükçe verimsizleşme başlar ve çoğunlukla dikey ölçeklendirmeye uygundur
Diğer yandan graf veritabanlarında:
- Veriler düğümler, kenarlar ve özellikleri içeren graf modeli ile saklanır
- İlişkiler doğrudan kenarlar olarak (birinci sınıf varlıklar) temsil edilir
- Genellikle şemasız veya esnek şema yapısı vardır
- Veri geçişleri sabir zamanda gerçekleşir, JOIN maliyeti yoktur
- Büyük boyutlu verilerle bile performanslı çalışır ve yatay ölçeklenebilirliği yüksektir
Forrester Research tarafından yapılan bir araştırmaya göre, 2017’den 2020’ye kadar graf veritabanlarının benimsenmesinde %210’luk önemli bir büyüme yaşanmıştır. Bu artış, ilişkisel veritabanlarının karmaşık ilişkileri verimli şekilde temsil etmede yaşadığı zorluklardan kaynaklanmaktadır.
Veri Bağlantılarını Önceliklendirme
Graf veritabanlarının en önemli özelliği, ilişkileri birinci sınıf varlıklar olarak ele almasıdır. İlişkisel veritabanlarının aksine, graf veritabanları ilişkilere öncelik verir. Bu yaklaşım, ilişkilerin hacmi ve derinliği arttıkça daha değerli hale gelir.
Özellikle karmaşık veri ilişkilerinde, ilişkisel veritabanlarda veri sorgulamak için çok sayıda tabloyu birleştirmek gerekir. Tablolar arasındaki bağlantılar karmaşıklaştıkça ve belirgin bir model izlemedikçe, JOIN işlemlerinin karmaşıklığı üstel olarak artabilir. Artık sadece iki veya üç tabloyu birleştirmek yeterli olmaz; doğru veri bağlantısını bulmak ve değerli analizler elde etmek için yedi veya daha fazla tabloyu birleştirmeniz gerekebilir. Bu durumda graf veritabanları ideal çözüm haline gelir.
Graf veritabanları aşağıdaki alanlarda üstün performans gösterir:
- Sosyal ağlar: Kullanıcılar arası karmaşık ilişkilerin modellenmesi
- Öneri sistemleri: Kullanıcı davranışlarına ve ilişkilerine dayalı öneriler
- Dolandırıcılık tespiti: Finansal işlemlerdeki şüpheli kalıpların belirlenmesi
- BT Ağ analizi: Sistemler arası bağlantıların incelenmesi
- Rota ve lojistik optimizasyonu: En verimli taşıma rotalarının belirlenmesi
Bunun yanı sıra, graf veritabanları veri modeli üzerinde esneklik sağlar. Bu esneklik sayesinde, yeniden yapılandırma olmaksızın yeni ilişkiler veya veri türleri kolayca eklenebilir. Ayrıca veri büyüdükçe ilişkilerde daha hızlı geçiş sağlar. LinkedIn’in “Tanıyor Olabileceğiniz Kişiler” özelliği, etkili bir şekilde graf modeli kullanan dikkate değer bir örnektir.
Graf veritabanlarında veriler düğümler, kenarlar ve özellikler şeklinde organize edilir:
- Düğümler (Nodes): Varlıkları temsil eder (kişiler, ürünler, hesaplar vb.)
- Kenarlar (Edges): Düğümler arasındaki ilişkileri temsil eder
- Özellikler (Properties): Hem düğümlere hem de kenarlara ait nitelikler
- Etiketler (Labels): Düğümleri veya kenarları kategorize etmek için kullanılır
Sonuç olarak, graf veritabanları özellikle yüksek düzeyde bağlantılı verilerde üstün performans gösterir. İlişkisel veritabanlarında karmaşık ilişkiler sorgularken kaynakları tüketen yavaş JOIN işlemleri gerekirken, graf veritabanları bu ilişkileri doğal ve verimli bir şekilde modelleyip sorgulayabilir. Bu da büyük ve karmaşık veri yapılarıyla çalışırken önemli bir avantaj sağlar.
Graf Veritabanlarının Temel Bileşenleri
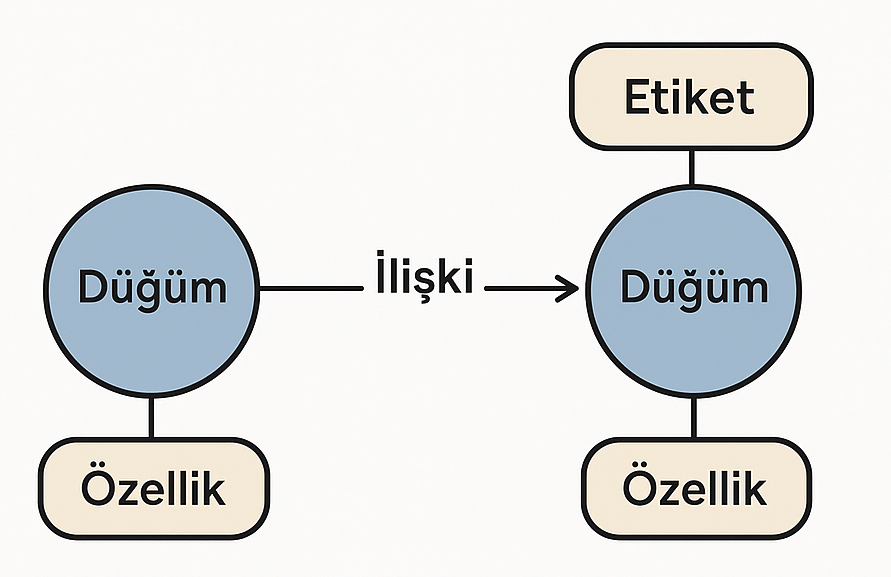
Bir graf veritabanının yapısını anlamak, üç temel bileşenini kavramakla mümkündür. Bu bileşenler – düğümler, kenarlar ve özellikler – birlikte karmaşık ilişkisel yapıların modellenmesini ve etkili veri sorgularını mümkün kılar. Bu bölümde, graf veritabanlarının temel yapı taşlarını detaylı olarak inceleyeceğiz.
Düğümler (Nodes) ve Etiketler
Düğümler, graf veritabanlarının en temel bileşenleridir ve veritabanında saklanan varlıkları temsil ederler. Bu varlıklar kişiler, ürünler, hesaplar veya modellemek istediğiniz herhangi bir nesne olabilir. Düğümler, geleneksel ilişkisel veritabanlarındaki tabloların kayıtlarına benzetilebilir, ancak çok daha esnek bir yapıya sahiptirler.
Etiketler (Labels) ise düğümleri kategorize etmek için kullanılan önemli tanımlayıcılardır. Etiketler sayesinde düğümleri gruplara ayırabilir ve veri sorgulamayı daha verimli hale getirebilirsiniz. Örneğin, bir sosyal medya graf veritabanında, bazı düğümlere “Kullanıcı” etiketi, diğerlerine ise “BlogYazısı” etiketi atanabilir.
Etiketlerin iki tamamlayıcı türü vardır:
- Şema tanımlı etiketler: Graf modelinin şema bölümünde açıkça tanımlanır ve önceden belirlenmiş özellikleriyle düğüm türlerini gösterir.
- Dinamik etiketler: Şema bölümünde önceden tanımlı değildir ve çalışma zamanında temel tablolardaki verilerden oluşturulabilir.
Neo4j gibi graf veritabanı sistemlerinde, her düğüm birden fazla etiket taşıyabilir. Bu, veritabanınızı daha esnek ve dinamik hale getirir. Ayrıca, düğümleri farklı bakış açılarından sınıflandırmanıza olanak tanır. Bu esneklik, özellikle veri modelinizin zaman içinde gelişmesi gerektiğinde büyük avantaj sağlar.
Kenarlar (Edges) ve Yönler
Kenarlar, düğümler arasındaki ilişkileri gösteren bağlantılardır ve graf veritabanlarının diğer veritabanı türlerinden en önemli farkını oluşturur. İlişkisel veritabanlarında tablolar arasındaki bağlantılar yabancı anahtarlarla sağlanırken, graf veritabanlarında ilişkiler doğrudan kenarlar olarak modellenebilir.
Kenarlar, yönlü veya yönsüz olabilir:
- Yönlü kenarlar (Directed edges): Bağlantının nereden başlayıp nerede bittiğini belirten yön bilgisini içerir. Örneğin, bir kullanıcının bir blog yazısını yazdığını göstermek için yönlü kenar kullanılır.
- Yönsüz kenarlar (Undirected edges): İki düğüm arasında karşılıklı bir ilişki olduğunu gösterir, belirli bir yön bilgisi taşımaz.
Bununla birlikte, kenarlar ağırlık (weight) değerleri taşıyabilir. Bu ağırlıklar, kenarların önem derecesini veya başka bir sayısal değeri temsil edebilir. Örneğin, bir şehir ağında kenarlar arasındaki ağırlıklar, şehirler arasındaki mesafeleri gösterebilir. Bu tür graflara ağırlıklı graf (weighted graph) adı verilir.
Kenarların derecesi, bir düğümü diğer düğümlere bağlayan kenarların sayısını ifade eder. Bir graftaki en yüksek düğüm derecesi, aynı zamanda o grafın derecesini belirler. Bu özellik, graf analizinde önemli bir ölçüttür ve sosyal ağ analizinde sıklıkla kullanılır.
Özellikler (Properties) ile Veri Zenginleştirme
Özellikler, hem düğümlere hem de kenarlara eklenebilen veri alanlarıdır. Bu özellikler, düğümleri ve kenarları daha ayrıntılı tanımlamak için kullanılır ve veri modelinizi zenginleştirir.
Düğüm özellikleri, ilişkisel veritabanlarındaki tablo sütunlarına benzer şekilde çalışır, ancak her düğüm türü için sabit bir şema zorunluluğu yoktur. Aynı etiketli düğümler farklı özelliklere sahip olabilir. Örneğin:
- “Kullanıcı” etiketli bir düğüm, isim, yaş ve şehir özelliklerine sahip olabilir.
- “Ürün” etiketli bir düğüm, isim, fiyat ve stok miktarı özelliklerine sahip olabilir.
Kenar özellikleri ise düğümler arasındaki ilişkileri daha ayrıntılı tanımlar. Örneğin, bir “takip ediyor” kenarı, takip başlangıç tarihi gibi bir özellik içerebilir veya bir “satın aldı” kenarı, satın alma tarihi ve miktarı gibi özelliklere sahip olabilir.
Neo4j gibi sistemlerde, bu model Labeled Property Graph (Etiketli Özellik Grafı) olarak adlandırılır. Bu model, düğümlere ve kenarlara etiketler ve özellikler ekleyerek graf yapısını zenginleştiren güçlü bir yaklaşımdır.
Özellikler sayesinde, graf veritabanınızda depolanan veriler daha anlamlı ve sorgular daha spesifik hale gelir. Ayrıca, özellikler üzerinde filtreleme yaparak daha hedefli sorgular oluşturabilirsiniz. Özellikle Neo4j gibi sistemlerde, düğüm ve kenar özelliklerini kullanarak karmaşık sorguları Cypher sorgu dili ile kolayca gerçekleştirebilirsiniz.
Sonuç olarak, düğümler, kenarlar ve özellikler – graf veritabanlarının üç temel bileşeni – birlikte çalışarak karmaşık ve ilişkisel verileri etkili bir şekilde modellemenizi sağlar. Bu bileşenler, veri tabanınızı daha esnek, anlamlı ve sorgulanabilir hale getirir.
Graf Veritabanı Nasıl Çalışır?
Geleneksel veritabanları ile kıyaslandığında, graf veritabanlarının çalışma prensipleri oldukça farklıdır. Bu veritabanları, ilişkileri birinci sınıf vatandaş olarak ele alır ve veri erişimini hızlandırmak için özel teknikler kullanır. Şimdi bu mekanizmaları daha yakından inceleyelim.
Index-Free Adjacency ile Hızlı Erişim
Graf veritabanlarının en önemli teknik özelliklerinden biri index-free adjacency (dizinsiz komşuluk) kavramıdır. Bu yaklaşım, düğümler arasındaki ilişkileri global bir dizin kullanmadan doğrudan fiziksel RAM adresleri ile saklar. Böylece, bir düğümden komşu düğümlere geçiş yaparken herhangi bir dizin araması yapmak gerekmez.
Geleneksel ilişkisel veritabanlarında bir JOIN işlemi yapmak için veritabanı, her seferinde bir dizin araması gerçekleştirir. Bu işlem, veritabanı büyüdükçe O(log n) karmaşıklığıyla yavaşlar. Oysa index-free adjacency kullanan graf veritabanlarında, bir düğümden komşu düğümlere erişim O(1) sabit zamanda gerçekleşir. Bu sayede, graf üzerinde dolaşmak (traversal) oldukça hızlıdır.
Aslında, bu teknoloji sayesinde bir sunucunun her çekirdeği saniyede yaklaşık bir milyon düğüm geçişi yapabilir. 16 çekirdekli tipik bir sunucuda saniyede 16 milyon geçiş mümkündür. Daha güçlü sunucularda ise bu sayı çok daha yüksektir.
Bunun yanı sıra, native graf veritabanları, veri yüklenirken (sorgulama sırasında değil) ilişkileri doğrudan bellek adreslerine dönüştürür. Örneğin bir kullanıcının takipçilerine erişmek için ilişkisel veritabanında karmaşık JOIN’ler gerekirken, graf veritabanında bu işlem doğrudan bellek erişimi ile gerçekleşir.
Graf Sorgulama Dilleri: Cypher, Gremlin, SPARQL
Graf veritabanları, ilişkileri ve bağlantıları sorgulamak için özel diller kullanır. Bu diller, düğümler ve kenarlar arasındaki ilişkileri anlamak ve verimli şekilde keşfetmek için tasarlanmıştır. En popüler üç graf sorgulama dili şunlardır:
| Sorgu Dili | Özellikler | Kullanım Alanları |
|---|---|---|
| Cypher | Neo4j için geliştirilmiş, ASCII-sanatı benzeri görsel sorgulama dili | Sosyal ağlar, öneri motorları |
| Gremlin | Apache TinkerPop çerçevesi ile çalışan, hem açıklayıcı hem de zorunlu sorgulama yapabilen dil | Sosyal ağlar, dolandırıcılık tespiti |
| SPARQL | RDF tabanlı graflar için W3C tarafından önerilen dil | Bilgi grafları, anlamsal web projeleri |
Cypher, SQL’e benzer ancak graf yapılarını sorgulamak için özel olarak tasarlanmış açıklayıcı bir dildir. Düğümleri parantez içinde
()
, ilişkileri ise köşeli parantez ve ok işaretleriyle
-[]->
gösterir. Bu görsel yapı, graf desenlerini tanımlamayı oldukça sezgisel hale getirir.
Diğer yandan Gremlin, graflar üzerinde adım adım ilerlemeye dayalı bir yaklaşım sunar. Bu dil, Groovy tabanlıdır ancak Java, JavaScript, Python gibi birçok programlama dili ile de kullanılabilir. Gremlin, karmaşık graf geçişleri ve algoritmaları için uygundur.
SPARQL ise özellikle anlamsal web projelerinde ve RDF (Resource Description Framework) tabanlı graf veritabanlarında yaygın olarak kullanılır. Özne-yüklem-nesne üçlüleri üzerinden sorgulama yapma imkanı sağlar.
Graf Algoritmaları: Arama, Kümeleme, Bölme
Graf veritabanları, graflar üzerinde çalışan çeşitli algoritmaları destekler. Bu algoritmalar, veriler arasındaki karmaşık ilişkileri analiz etmek ve anlamlı desenler bulmak için kullanılır:
Arama Algoritmaları: En kısa yol bulma, erişilebilirlik ve bağlantı testi gibi işlemler için kullanılır. Örneğin, bir sosyal ağda iki kullanıcı arasındaki en kısa bağlantıyı bulmak veya bir ulaşım ağında en hızlı rotayı hesaplamak için Dijkstra veya BFS (Breadth-First Search) algoritmaları kullanılabilir.
Kümeleme Algoritmaları: Benzer düğümleri gruplamak için kullanılır. Özellikle topluluk tespiti, öneri sistemleri ve veri segmentasyonu için değerlidir. Graf kümeleme kalitesini ölçmek için genellikle modülarite kullanılır.
Bölme Algoritmaları: Bir grafı daha küçük ve yönetilebilir parçalara ayırmak için kullanılır. Büyük ölçekli grafları işlemek veya paralel hesaplama yapmak gerektiğinde önemlidir.
Bu algoritmaların graf veritabanlarında doğrudan uygulanması, karmaşık analizlerin ve sorguların verimli şekilde gerçekleştirilmesini sağlar. Örneğin, bir sosyal ağda etki sahibi kullanıcıları bulmak, dolandırıcılık desenlerini tespit etmek veya öneri sistemleri oluşturmak için bu algoritmalar kullanılabilir.
Ayrıca graf algoritmaları, verilerdeki gizli desenleri ortaya çıkarmada da son derece etkilidir. Özellikle gerçek zamanlı analitik işlemlerde, geleneksel veritabanlarına göre çok daha hızlı sonuçlar üretebilirler.
Graf Veritabanı Kullanım Alanları
Graf veritabanlarının benzersiz özellikleri, birçok sektörde karmaşık veri ilişkilerini modellemek için ideal çözümler sunar. İlişkisel veritabanlarının yetersiz kaldığı senaryolarda, graf veritabanları performans ve esneklik avantajlarıyla öne çıkar. Şimdi bu güçlü teknolojinin en yaygın kullanım alanlarını inceleyelim.
Gerçek Hayat Örnekleri
- LinkedIn, “Tanıyor olabileceğiniz kişiler” önerisini graf modeli üzerinden çalıştırır. Düğümler kullanıcıları, kenarlar ise etkileşimleri temsil eder.
- Amazon, kullanıcılar ve ürünler arasındaki alışveriş, inceleme, görüntüleme ilişkilerini graf yapısında analiz ederek öneri sistemlerini zenginleştirir.
- HSBC gibi büyük bankalar, dolandırıcılığı tespit etmek için kullanıcılar arası para transferlerini ve iletişim bilgilerini analiz eden graf tabanlı tespit sistemleri kullanır.
Sosyal Ağ Analizi
Sosyal ağlar, graf veritabanlarının en doğal uygulama alanıdır. Kullanıcılar düğüm olarak, aralarındaki etkileşimler ise kenar olarak modellenebilir. Facebook, LinkedIn ve Twitter gibi platformlar, kullanıcılar arasındaki arkadaşlık, takip etme ve etkileşim ilişkilerini graf yapısında saklayarak analiz eder.
Bu tür sistemlerde, kullanıcılar köşeleri oluştururken, takipçileriyle olan ilişkileri kenarları oluşturur. Graf veritabanları sayesinde:
- Kullanıcılar arasındaki bağlantı yolları hızlıca bulunabilir
- Topluluk tespiti ve etki analizi kolaylaşır
- Kullanıcı davranışları ve etkileşim kalıpları ortaya çıkarılabilir
Bununla birlikte, sosyal ağ analizinde (SNA) veri toplama, sınıflandırma, örüntü tanımlama ve görselleştirme için özel yöntemler kullanılır. Bu sayede ilişkisel veriler sosyal ağ yapısında modellenebilir ve karmaşık bağlantılar görselleştirilebilir.
Öneri Sistemleri
E-ticaret siteleri ve medya platformları, müşterilerine kişiselleştirilmiş öneriler sunmak için graf veritabanlarından yararlanır. Kullanıcıların ortak ilgi alanlarını ve davranış kalıplarını tespit ederek benzer özelliklere sahip ürünleri veya içerikleri önerebilirler.
Özellikle graf veritabanları, iki alakasız nesne arasındaki ortak noktaları tespit etme konusunda üstün yeteneklere sahiptir. Örneğin, arkadaşlarınızın takip ettiği ancak sizin takip etmediğiniz kişileri bulup öneri olarak sunabilir. Ayrıca, benzerlik tahmini yaparak alışveriş tavsiye sistemleri oluşturmak için de kullanılır.
Dolandırıcılık Tespiti
Finansal kuruluşlar için dolandırıcılık tespiti, graf veritabanlarının en değerli kullanım alanlarından biridir. Karmaşık ilişki örüntülerini analiz ederek, geleneksel sistemlerin tespit edemediği şüpheli işlemleri belirlemede etkilidir.
İşletmeler her yıl gelirlerinin yaklaşık %5’ini dolandırıcılık nedeniyle kaybetmektedir. Geleneksel yaklaşımlar genellikle ayrı veri noktalarına odaklanırken, graf veritabanları ilişkileri bir bütün olarak ele alır. Bu sayede:
- Ortak telefon numaraları, e-posta adresleri gibi bağlantılar tespit edilebilir
- Dolandırıcılık halkaları görselleştirilebilir
- Şüpheli işlemler gerçek zamanlı olarak analiz edilebilir
Özellikle, grafik veritabanı kullanarak oluşturulan dolandırıcılık grafları, birden çok kişinin aynı iletişim bilgilerini paylaştığı durumları kolayca ortaya çıkarabilir. Bu şekilde dolandırıcılık çeteleri tespit edilip finansal risk hesaplanabilir.
Rota ve Lojistik Optimizasyonu
Graf veritabanları, karmaşık ulaşım ağlarını modellemek ve en verimli rotaları belirlemek için idealdir. Lojistik ve rota optimizasyonu, ürünleri bir yerden başka bir yere taşımak için en hızlı ve en uygun maliyetli yolu planlamayı içerir.
Rota optimizasyon sistemleri:
- Teslimat mesafeleri, lokasyonlar ve araç kapasiteleri gibi verileri toplar
- Optimizasyon algoritmaları uygulayarak en verimli rotaları belirler
- Trafik koşullarını, teslimat zaman aralıklarını ve müşteri tercihlerini dikkate alır
Ayrıca, lojistik yönetiminde dağıtım merkezlerinin nereye yerleştirileceğine karar vererek lojistik iletme maliyetini en aza indirmeyi amaçlayan sistemler geliştirilmiştir. Böylece dağıtım ağı yapısı, sistem genelindeki toplam maliyeti en aza indirmek için depolama, envanter ve nakliye maliyetleri arasında denge sağlar.
Bilgi Grafı ve Anlamsal Arama
Bilgi grafları, varlıklar ve bunlar arasındaki ilişkileri içeren geniş bilgi ağlarıdır. Graf veritabanları, bu karmaşık bilgi yapılarını modellemek için mükemmel araçlardır. Google gibi arama motorları, arama sonuçlarını zenginleştirmek için bilgi graflarını kullanır.
Google, web sitelerinin her birinin köşe ve birbirlerine verdikleri linklerin kenar olduğu bir graf yapısında modellenebilir. Bu sayede web sayfaları arasındaki bağlantılar analiz edilebilir ve arama sonuçları geliştirilebilir.
Sonuç olarak, graf veritabanları birçok sektörde veri ilişkilerini anlamak ve analiz etmek için kullanılmaktadır. Veri uzmanları olarak bizler, her geçen gün daha fazla kullanım alanı keşfediyor ve bu teknolojinin potansiyelini en üst düzeye çıkarıyoruz.
Graf Veritabanlarının Avantajları
Modern veri yönetimi dünyasında graf veritabanları, ilişkisel veritabanlarına kıyasla belirgin avantajlar sunar. Bu veri depolama teknolojisinin öne çıkan özellikleri, karmaşık ve bağlantılı verilerle çalışan sistemlerde açıkça görülür. Geleneksel yaklaşımların yetersiz kaldığı noktaları aşan graf veritabanları, neden giderek daha fazla kuruluşun tercih ettiği bir çözüm haline geliyor?
Şema Esnekliği ve Evrimsel Modelleme
Graf veritabanlarının en büyük avantajlarından biri, veri yapısını esnek bir şekilde modelleyebilme yeteneğidir. İlişkisel veritabanlarının aksine, graf veritabanları önceden tanımlanmış katı bir şema gerektirmez. Bu esneklik, veri modelinizin ihtiyaçlarınıza göre zaman içinde evrilmesine olanak tanır.
Graf yapısının sunduğu esneklik sayesinde:
- Yeni düğümleri, kenarları ve özellikleri şema değişikliği gerektirmeden kolayca ekleyebilirsiniz
- Veri saklama ve geliştirmede özgürlük kazanırsınız
- Veri modeli ihtiyaç doğrultusunda dinamik olarak şekillendirilebilir
- Mevcut yapıya zarar vermeden yeni ilişki türleri tanımlayabilirsiniz
Bununla birlikte, veritabanı dizaynında esneklik sağlayan bu yaklaşım, iş gereksinimleri değiştikçe veritabanınızın da buna uyum sağlamasını kolaylaştırır. Özellikle etiketli özellik grafı (Labeled Property Graph) modelini kullanan Neo4j gibi sistemlerde, şema değişikliği olmadan yeni veri tiplerini entegre etmek mümkündür.
Diğer yandan, grafik yapısı ihtiyaç doğrultusunda şekillendirilebilir olduğundan, veri modelinizi baştan tasarlamanıza gerek kalmaz. Bu da yazılım geliştirme süreçlerinde evrimsel bir yaklaşım benimseyebilmeyi sağlar. TigerGraph gibi daha esnek sistemler, veri öğelerinin gerektiğinde düğüm, gerektiğinde öznitelik olarak kullanımına imkan vererek modellemede maksimum esneklik sunar.
Gerçek Zamanlı Sorgu Performansı
Graf veritabanlarının teknik açıdan en önemli avantajlarından biri, gerçek zamanlı sorgu performansıdır. Bu veritabanları, indekssiz komşuluk (index-free adjacency) sistemini kullanarak verileri saklar ve işler. Bir düğümden komşu düğümlere her geçiş, global indeks aramaları olmadan doğrudan bellek işaretçileri üzerinden gerçekleşir.
İlişkisel veritabanlarının aksine, graf veritabanları JOIN işlemleri veya indis aramaları içermeye ihtiyaç duymadan her öğenin komşu olduğu bir öğeye doğrudan bir işaretçi içermesini sağlar. Örneğin, Microsoft’un graf modelleri sunduğu sistemlerde, grafik gerçekleştirilmiş anlık görüntüler sayesinde her sorgu için grafikleri yeniden oluşturma gereksinimi ortadan kalkar ve bu da sorgu performansını önemli ölçüde iyileştirir.
Ayrıca, yüksek performanslı graf işleme özelliği sayesinde, bir sunucunun her çekirdeği saniyede yaklaşık bir milyon düğüm geçişi yapabilir. Bu da karmaşık ve büyük veri kümeleriyle çalışırken bile hızlı yanıt süreleri sağlar.
Yüksek Bağlantılı Verilerde Verimlilik
Graf veritabanları, özellikle yoğun ilişkilerle dolu veri kümelerinde üstün verimlilik gösterir. Karmaşık ilişkilere sahip verileri depolama, sorgulama ve analiz etme konusunda yüksek performans sergiler ve birçok kullanım durumunda ilişkisel veritabanlarından daha iyi sonuçlar üretir.
Örneğin, sosyal ağlar, öneri sistemleri ve dolandırıcılık tespiti gibi alanlarda, graf veritabanları ilişkisel veritabanlarına göre çok daha verimli çalışır. Bunun temel nedeni, ilişkileri birincil sınıf vatandaş olarak ele alması ve bu ilişkilerin derinliği ve hacmi arttıkça performansının iyileşmesidir.
Büyük ölçekli graf işleme sistemleri son yıllarda ciddi bir ilerleme göstermiş olup, yapılandırılmamış graf verilerinin işlenmesi, hız, hata oranını azaltma, akan veri biçimlendirme ve bölümleme konusunda önemli avantajlar sunar. Bu sistemler özellikle benzerlik tahmini, pagerank, en kısa yol, oyun teorisi, biyoenformatik ve şebeke sistemleri gibi alanlarda kritik öneme sahiptir.
Sonuç olarak, graf veritabanları şema esnekliği, gerçek zamanlı sorgu performansı ve yüksek bağlantılı verilerdeki verimliliği ile karmaşık veri ilişkilerini modellemek ve sorgulamak için ideal bir çözüm sunar. Bu avantajlar, özellikle ilişkilerin kritik öneme sahip olduğu senaryolarda geleneksel veritabanlarına göre daha üstün bir alternatif oluşturur.
Graf Veritabanlarının Sınırlamaları
Tüm avantajlarına rağmen, graf veritabanları her senaryoda mükemmel çözümler sunmaz ve bazı teknik sınırlamaları bulunur. Bu sınırlamalar, kullanım senaryonuza ve veri yapınıza bağlı olarak projelerinizde önemli faktörler olabilir. Graf veritabanlarını değerlendirirken, sunduğu fırsatların yanında bu kısıtlamaları da dikkate almak gerekir.
Yatay Ölçeklenebilirlikte Zorluklar
Graf veritabanları, özellikle verilerin boyutu büyüdükçe yatay ölçeklenebilirlikte çeşitli zorluklarla karşılaşır. Geleneksel ilişkisel veritabanları genellikle yatay ölçeklenebilirlikle mücadele eder ve dikey ölçeklendirmeye (daha büyük bir makine kullanma) güvenir. Bu yaklaşım maliyetli olabilir ve belirli sınırlamaları vardır.
Büyük ölçekli graf işlemede karşılaşılan temel zorluklar:
- Tek bir makine, büyük graflar için gerekli depolama ihtiyacını karşılayamaz, bu nedenle hiper ölçekli grafikler için dağıtılmış depolama gereklidir
- Grafın düzensiz yapısından dolayı donanım kaynakları yeterince verimli kullanılamaz
- Büyük graflar için rastgele disk erişimi performans darboğazına dönüşebilir
Diğer yandan, veri bölümleme (data partitioning) graf veritabanlarında karmaşık bir konudur. Grafın doğası gereği, veri bölümleri arasında yüksek düzeyde bağlantı olabilir ve bu da bölümler arası iletişimi artırarak performansı düşürebilir. Veri dağıtımı, veri çoğaltma veya parçalama yoluyla gerçekleştirilmekte ancak her iki yöntemin de dezavantajları bulunmaktadır.
Basit Veri Yapılarında Aşırı Maliyet
Graf veritabanlarının en büyük dezavantajlarından biri, daha yüksek öğrenim ve uygulama maliyetleridir. Özellikle karmaşık yapıların yönetimi ve optimize edilmesi, özel uzmanlık gerektirebilir. Basit veri yapıları ve ilişkileri için graf veritabanı kullanmak, gereksiz bir karmaşıklık ve maliyet getirebilir.
Bununla birlikte, aşağıdaki durumlarda graf veritabanları aşırı çözüm olabilir:
- Veri modeli az sayıda bağlantı içeriyorsa
- İlişkiler sadece birkaç tabloyu kapsıyorsa
- Veri analizi karmaşık ilişki sorgularını gerektirmiyorsa
- İlişkisel şemalar verileri yeterince iyi modelleyebiliyorsa
Ayrıca, graf veritabanları için standardizasyon eksikliği söz konusudur. SQL gibi standart bir sorgu dili yoktur ve her graf veritabanı türünün (hatta aynı türdeki farklı veritabanlarının) kendi sorgulama mekanizmaları ve API’leri vardır. Bu durum, öğrenme eğrisini dikleştirir ve sistemler arası geçişleri zorlaştırabilir.
Toplu Güncellemelerde Performans Sorunları
Graf veritabanları genellikle nihai tutarlılık (eventual consistency) modelini kullanır ve bu, bazı uygulamalar (örneğin bankacılık) için kabul edilemez olabilecek anlık veri tutarsızlıklarına yol açabilir. Verinin tüm kopyalarının senkronize olması zaman alabilir ve bu süreçte veri bütünlüğü sorunları oluşabilir.
Toplu güncelleme işlemleri sırasında performans sorunları şu sebeplerden kaynaklanabilir:
- Düğümler ve kenarlar arasındaki karmaşık bağlantılar, toplu güncellemeleri zorlaştırır
- Büyük graflar bellekte depolanamadığından, toplu işlemler için rastgele disk erişimi gerekir
- Graf güncellemesi sırasında oluşabilecek tutarsızlıklar, sistemin bütünlüğünü tehdit edebilir
Graf veritabanları, özellikle ilişkisel veritabanlarında JOIN işlemleri gibi karmaşık sorgular ve raporlamalar söz konusu olduğunda zorluklar yaşayabilir. Ayrıca, SQL kadar uzun bir geçmişe sahip olmadıkları için bazı alanlarda (yönetim araçları, güvenlik özellikleri, uzman sayısı) ekosistemleri daha az olgun olabilir.
Sonuç olarak, graf veritabanları birçok avantaj sunsa da, her projeye uygun olmayabilir. Projenizin ihtiyaçlarını dikkatle değerlendirmek ve graf veritabanlarının sınırlamalarını göz önünde bulundurmak, doğru veritabanı seçimi için kritik öneme sahiptir.
Graf Veritabanı Örneği: Sosyal Ağ Uygulaması
Sosyal ağlar, insan ilişkilerinin doğal bir grafik yapısında olması nedeniyle graf veritabanları için mükemmel bir uygulama alanıdır. Sosyal medya platformları kullanıcıları düğüm, aralarındaki etkileşimleri ise kenar olarak modelleyerek verileri saklar ve analiz eder. Bu bölümde, bir sosyal ağ uygulamasının graf veritabanı ile nasıl gerçekleştirilebileceğini inceliyoruz.
Kullanıcılar Arası İlişkilerin Modellenmesi
Sosyal ağlarda, kullanıcılar ve aralarındaki ilişkiler doğal bir graf yapısı oluşturur. Bu yapıda:
- Düğümler: Kullanıcıları temsil eder ve ad, yaş, konum gibi özellikleri içerir
- Kenarlar: Arkadaşlık, takip etme, beğenme gibi ilişkileri gösterir
- Özellikler: Hem düğümlere hem de kenarlara ait olabilir (örneğin, arkadaşlık başlangıç tarihi)
Örneğin, bir kullanıcının bir fotoğrafı paylaşması ve başka bir kullanıcının bunu beğenmesi şöyle modellenebilir:
// Kullanıcı düğümü oluşturma
MATCH (a:User { Name: 'Ece' }), (b:Photo { Name: 'PlajFotosu_01' })
CREATE (a)-[:HAS {Year: 2015}]->(b)
// Beğenme ilişkisi ekleme
MATCH (a:User { Name: 'Serhat' }), (b:Photo { Name: 'PlajFotosu_01' })
CREATE (a)-[:LIKE]->(b)
Bu şekilde, kullanıcılar, paylaştıkları içerikler ve diğer kullanıcılarla etkileşimleri tek bir bütünleşik graf yapısında modellenebilir. Bununla birlikte, bu model sosyal ağların karmaşık yapısını doğal olarak temsil etme avantajına sahiptir.
Arkadaşlık Sorgularının Gerçeklenmesi
Sosyal ağlarda en sık yapılan sorgulardan biri, iki kullanıcı arasındaki arkadaşlık ilişkilerini bulmaktır. Graf veritabanları, bu tür sorguları geleneksel veritabanlarına göre çok daha verimli şekilde gerçekleştirebilir.
Örneğin, bir kullanıcının takip ettiği ve etmediği kişileri bulmak için şu sorgu kullanılabilir.
// Serhat'ın takip ettiği kişileri bulma
MATCH (a:User { Name: 'Serhat' })-[:FOLLOW]->(b:User)
RETURN b.Name
// Serhat'ın arkadaşlarının takip ettiği ama kendisinin takip etmediği kişileri bulma
MATCH (a:User { Name: 'Serhat' })-[:FOLLOW]->(friend),
(friend)-[:FOLLOW]->(friendOfFriend)
WHERE NOT (a)-[:FOLLOW]->(friendOfFriend)
AND a <> friendOfFriend
RETURN DISTINCT friendOfFriend.Name
Özellikle, “arkadaşlarımın takip ettiği ama benim takip etmediğim kişiler kimler?” gibi sorgular graf veritabanlarının güçlü olduğu alanlardır. Sosyal ağ analizi (SNA) kullanılarak toplulukların tespiti, etki sahibi kullanıcıların belirlenmesi ve kullanıcı davranışlarının analizi de kolaylıkla yapılabilir.
Relational vs Graph Yaklaşımı Karşılaştırması
Sosyal ağ uygulamaları için ilişkisel ve graf veritabanı yaklaşımları arasında önemli farklar vardır:
| Özellik | İlişkisel Yaklaşım | Graf Yaklaşımı |
|---|---|---|
| İlişki Gösterimi | Yabancı anahtarlar ve çok sayıda JOIN | Doğrudan kenarlar |
| Performans | Bağlantı sayısı arttıkça düşer | Bağlantı sayısı arttıkça değişmez |
| Sorgu Karmaşıklığı | Karmaşık JOIN işlemleri | Görsel ve sezgisel |
| Ölçeklenebilirlik | Veri büyüdükçe verimsizleşir | Veri büyüdükçe aynı performans |
İlişkisel veritabanlarında aynı sorguyu yapmak için:
SELECT DISTINCT c.CompanyName
FROM customers AS c
JOIN orders AS o ON (c.CustomerID = o.CustomerID)
JOIN order_details AS od ON (o.OrderID = od.OrderID)
JOIN products AS p ON (od.ProductID = p.ProductID)
WHERE p.ProductName = 'Chocolade';
Diğer yandan, graf veritabanında aynı sorgu:
MATCH (p:Product {productName:'Chocolade'})<-[:ORDERS]-(:Order)<-[:PURCHASED]-(c:Customer)
RETURN DISTINCT c.companyName;
Bu karşılaştırma, graf veritabanlarının karmaşık ilişkileri sorgulama konusundaki üstünlüğünü açıkça gösterir. İlişkisel veritabanlarında, verileri tablolar halinde düzenlemenin ve JOIN işlemleriyle ilişkilendirmenin karmaşıklığı, özellikle sosyal ağlar gibi yoğun bağlantılı sistemlerde belirgin hale gelir.
Facebook gibi büyük sosyal ağlar, milyarlarca kullanıcı ve bunlar arasındaki karmaşık ilişkileri yönetmek için graf veritabanlarından yararlanır. Bu yapı sayesinde, “arkadaşının arkadaşı” önerileri veya karmaşık topluluk analizleri gibi işlemler hızlı ve verimli şekilde gerçekleştirilebilir.
Popüler Graf Veritabanı Sistemleri
Piyasada çeşitli ihtiyaçlara cevap veren birçok graf veritabanı sistemi bulunmaktadır. Her biri kendine özgü özelliklere, sorgu dillerine ve veri modellerine sahip olan bu sistemler, farklı uygulama senaryolarına hizmet eder. Şimdi, en popüler graf veritabanı sistemlerini ve bunların ayırt edici özelliklerini inceleyelim.
Neo4j ile Labeled Property Graph Modeli
Neo4j, dünya çapında en yaygın kullanılan graf veritabanıdır ve Labeled Property Graph (Etiketli Özellik Grafı) modelini kullanır. Bu modelde, düğümler ve kenarlar etiketler ve özelliklerle zenginleştirilir. Neo4j’nin öne çıkan özellikleri:
- Cypher adlı görsel ve sezgisel sorgu dili sunar
- ACID uyumlu işlemler ve gelişmiş ölçeklendirme yetenekleri sağlar
- Düğümleri sınıflandırmak için etiketleme sistemi kullanır
- İndex-free adjacency (dizinsiz komşuluk) ile hızlı sorgu performansı sunar
Neo4j’de düğümler ve kenarlar belirli özelliklerle tanımlanır ve her düğüm birden fazla etiket taşıyabilir. Bu esneklik, farklı bakış açılarından sınıflandırma yapabilmeyi mümkün kılar.
Amazon Neptune ile RDF ve SPARQL Desteği
Amazon Neptune, bulut üzerinde çalışan tam yönetilen bir graf veritabanı hizmetidir. Özellikle RDF (Resource Description Framework) desteği ile öne çıkar:
- Hem property graph hem de RDF modellerini destekler
- SPARQL 1.1 sorgu dili ile uyumludur
- Web için tasarlanmış graf veri formatını kullanır
- SELECT, ASK, CONSTRUCT ve DESCRIBE gibi SPARQL sorgu türlerini destekler
Neptune, SPARQL sorgularıyla düğümler arasındaki ilişkileri analiz etmeyi kolaylaştırır. Ayrıca, federasyon özellikleri sayesinde farklı veri kaynaklarına bağlanarak sorgu yapabilme yeteneği sunar. Ancak, Neptune’un IAM kimlik doğrulama gereksinimlerini dikkate almak önemlidir.
ArangoDB ve OrientDB ile Çoklu Model Desteği
Çoklu model veritabanları, tek bir sistem içinde farklı veri modellerini destekleyen esnek çözümlerdir:
- ArangoDB: Graf, döküman ve anahtar-değer modellerini birleştirir. Özel edge indeksi kullanarak verimli graf sorguları sunar ve tek bir sorgu dili (AQL) ile tüm modellere erişim sağlar. Yatay ölçeklendirme yeteneği ile büyük veri setlerini işleyebilir.
- OrientDB: İkinci nesil dağıtık graf veritabanı olarak, hem döküman hem de graf modellerini tek üründe birleştirir. Çoğaltma ve parçalama özellikleri sunar. OrientDB saniyede 220.000 kayıt işleyebilme kapasitesine sahiptir ve hem şemasız hem de tam şema modlarını destekler.
Bu çoklu model yaklaşımı, farklı veri yapılarını tek bir veritabanında yönetebilme esnekliği sağlar ve karmaşık veri entegrasyonu gereksinimlerini basitleştirir.
Sonuç
Sonuç olarak, graf veritabanları karmaşık ilişkisel verileri modellemek için güçlü çözümler sunar. Bu makalede gördüğümüz gibi, düğümler, kenarlar ve özelliklerden oluşan yapısı sayesinde graf veritabanları ilişkileri birinci sınıf vatandaş olarak ele alır. Özellikle sosyal ağlar, öneri sistemleri, dolandırıcılık tespiti ve rota optimizasyonu gibi alanlarda üstün performans gösterir.
İlişkisel veritabanlarıyla karşılaştırıldığında, index-free adjacency teknolojisi graf veritabanlarına gerçek zamanlı sorgu performansı kazandırır. Ayrıca şema esnekliği, veri modelinin zaman içinde evrilmesine olanak tanır. Bununla birlikte, her teknolojide olduğu gibi graf veritabanlarının da sınırlamaları bulunur. Yatay ölçeklenebilirlik zorlukları, basit veri yapılarında fazla maliyet ve toplu güncellemelerdeki performans sorunları dikkate alınması gereken hususlardır.
Neo4j, Amazon Neptune, ArangoDB ve OrientDB gibi popüler sistemler farklı özellikleriyle çeşitli ihtiyaçlara cevap verir. Bu sistemlerin seçimi, projelerinizin gereksinimlerine bağlı olarak değişir. Graf veritabanlarını ne zaman kullanmanız gerektiğini anlamak için temel soru şudur: “Verimde ilişkiler ve bağlantılar birincil öneme sahip mi?” Eğer cevabınız evetse, graf veritabanı doğru seçim olabilir.
Veri miktarı ve karmaşıklığı arttıkça, ilişkilerin önem kazandığı dünyamızda graf veritabanları giderek daha değerli hale geliyor. Geleneksel yaklaşımların yetersiz kaldığı noktada, graf veritabanları bize veri denizinde yeni yollar açarak ilişkileri keşfetmemizi sağlar. Bu temel rehber, graf veritabanlarının dünyasına adım atmanız için başlangıç noktası olarak hizmet edecektir. Unutmayın ki veri bağlantılarının gücünü anlamak, modern veri analitiğinin anahtarıdır.
SSS
S1. Graf veritabanı nedir ve geleneksel veritabanlarından nasıl farklıdır? Graf veritabanı, verileri düğümler ve kenarlar olarak modelleyen özel bir veritabanı türüdür. Geleneksel veritabanlarından farklı olarak ilişkileri birincil sınıf varlıklar olarak ele alır ve karmaşık bağlantılı verileri daha verimli şekilde işler.
S2. Graf veritabanlarının en yaygın kullanım alanları nelerdir? Graf veritabanları genellikle sosyal ağ analizi, öneri sistemleri, dolandırıcılık tespiti, rota optimizasyonu ve bilgi grafları gibi alanlarda kullanılır. Bu alanlarda karmaşık ilişkileri modellemek ve analiz etmek için idealdir.
S3. Graf veritabanlarının avantajları nelerdir? Graf veritabanlarının başlıca avantajları arasında şema esnekliği, gerçek zamanlı sorgu performansı ve yüksek bağlantılı verilerde verimlilik bulunur. Özellikle karmaşık ilişkileri sorgulama konusunda üstün performans gösterirler.
S4. Graf veritabanlarının sınırlamaları nelerdir? Graf veritabanlarının bazı sınırlamaları arasında yatay ölçeklenebilirlikte zorluklar, basit veri yapılarında aşırı maliyet ve toplu güncellemelerde performans sorunları yer alır. Ayrıca, öğrenme eğrisi daha dik olabilir ve standardizasyon eksikliği söz konusudur.
S5. Popüler graf veritabanı sistemleri hangileridir? En popüler graf veritabanı sistemleri arasında Neo4j, Amazon Neptune, ArangoDB ve OrientDB bulunur. Neo4j etiketli özellik grafı modelini kullanırken, Amazon Neptune RDF desteği sunar. ArangoDB ve OrientDB ise çoklu model desteği ile öne çıkar.