
Bu blog yazısında , MacBook ortamında Docker ile SQL Server 2025 Public Preview kurulumu, Ollama modeli ile metin embedding üretimi ve bu embedding’lerin SQL Server içerisinde semantic search (anlam bazlı arama) amaçlı nasıl kullanılabileceğini adım adım göreceğiz. Tüm süreç yerel (local) olarak çalışacak şekilde tasarlanmıştır.
Ön Koşullar
- macOS (Apple Silicon M1/M2 önerilir)
- Docker Desktop
- Python 3.11+
- Ollama (nomic-embed-text modeliyle)
- Microsoft ODBC Driver 18 for SQL Server
- pyodbc, requests, numpy Python kütüphaneleri
1. SQL Server 2025 Docker Kurulumu
Aşağıdaki komutlarla SQL Server 2025 Public Preview container’ı başlatılır.
docker pull mcr.microsoft.com/mssql/server:2025-latest

docker run -e 'ACCEPT_EULA=Y' \
-e 'MSSQL_SA_PASSWORD=YourStrongPassword1!' \
-p 1433:1433 \
--name sql2025 \
-d mcr.microsoft.com/mssql/server:2025-latest

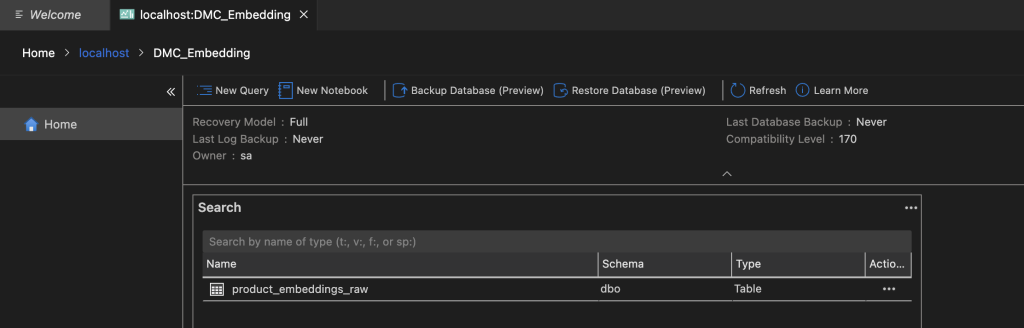
2. SQL Server Veritabanı ve Tablo Oluşturma
Azure Data Studio ile bağlandıktan sonra aşağıdaki komutları çalıştırın.
CREATE DATABASE DMC_Embedding;
GO
USE DMC_Embedding;
GO
CREATE TABLE product_embeddings_raw (
id INT PRIMARY KEY,
product_name NVARCHAR(255),
embedding NVARCHAR(MAX)
);
3. Ollama Kurulumu ve Model Çalıştırma
brew install ollama
ollama run nomic-embed-text

Model başlatıldığında Ollama sunucusu 11434 portunu dinleyecektir.

4. Embedding Üretimi ve SQL’e Yazma (ollama2sql.py)
Aşağıdaki Python betiği embedding üretip SQL Server’a kaydeder.
import requests
import pyodbc
def get_embedding(prompt):
res = requests.post("http://localhost:11434/api/embeddings", json={
"model": "nomic-embed-text",
"prompt": prompt
})
return res.json()["embedding"]
conn = pyodbc.connect("DRIVER={ODBC Driver 18 for SQL Server};SERVER=localhost,1433;DATABASE=DMC_Embedding;UID=sa;PWD=YourStrongPassword1!;TrustServerCertificate=yes")
cursor = conn.cursor()
def insert_raw_embedding(product_id, product_name, vector):
import json
json_vector = json.dumps(vector)
query = "INSERT INTO product_embeddings_raw (id, product_name, embedding_text) VALUES (?, ?, ?)"
cursor.execute(query, (product_id, product_name, json_vector))
conn.commit()
print("✅ Embedding yazıldı.")
# Kullanım
prompt = "SQL Server 2025 semantic search destekliyor mu?"
vector = get_embedding(prompt)
insert_raw_embedding(999, prompt, vector)
ollama2sql.py çalıştırdıktan sonra embedding yazılır.

5. Semantic.py ile Anlam Bazlı Arama
Kullanıcıdan alınan sorgu embedding’e çevrilip tüm kayıtlarla cosine similarity karşılaştırması yapılır.
import requests
import pyodbc
import json
import numpy as np
def get_embedding(prompt):
res = requests.post("http://localhost:11434/api/embeddings", json={
"model": "nomic-embed-text",
"prompt": prompt
})
return np.array(res.json()["embedding"])
def cosine_similarity(v1, v2):
return float(np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2)))
conn = pyodbc.connect("DRIVER={ODBC Driver 18 for SQL Server};SERVER=localhost,1433;DATABASE=DMC_Embedding;UID=sa;PWD=YourStrongPassword1!;TrustServerCertificate=yes")
cursor = conn.cursor()
prompt = "SQL Server'da benzer cümleleri nasıl bulurum?"
new_vector = get_embedding(prompt)
cursor.execute("SELECT id, product_name, embedding_text FROM product_embeddings_raw")
rows = cursor.fetchall()
best_match = None
best_score = -1
for row in rows:
existing_vector = np.array(json.loads(row.embedding_text))
score = cosine_similarity(new_vector, existing_vector)
if score > best_score:
best_score = score
best_match = row
print(f"🟢 ID: {best_match.id}, Name: {best_match.product_name}, Similarity: {best_score:.4f}")

Sonuç
Bu yapı sayesinde, SQL Server 2025’in henüz VECTOR veri tipini desteklememesine rağmen, anlam bazlı metin karşılaştırmalarını başarıyla gerçekleştirdik.Embedding üretimini Ollama modeli aracılığıyla dış ortamda yaparak, sonuçları veritabanına JSON formatında kaydettik.Benzerlik ölçümünü ise Python tarafında, cosine similarity algoritmasıyla hesaplayarak semantic search senaryomuzu tamamladık.
Özellikle semantic.py dosyasında yer alan prompt ifadesini değiştirip script’i yeniden çalıştırdığınızda, anlamsal benzerlik değerlerindeki farklılığı net biçimde gözlemleyebilirsiniz.Bu da semantic search’ün metin düzeyinde değil, kavramsal düzeyde nasıl çalıştığını göstermesi açısından oldukça öğretici bir deneyimdir.

Ek: Neden Python Kullandık?
SQL Server 2025 Public Preview sürümünde ‘AI_RUNTIME‘ bileşeni Docker imajlarında pasif durumda. Bu nedenle, veritabanı içerisinde doğrudan `AI_GENERATE_EMBEDDINGS` gibi fonksiyonlar kullanılamıyor. Embedding üretimi yapılmak istendiğinde SQL Server dışından bir araçla (örneğin Python) bu işlemi gerçekleştirmek gerekiyor.
Python tercih edilmesinin sebepleri:
- Ollama’yı HTTP üzerinden kolayca çağırabilmesi
- JSON formatındaki embedding vektörünü SQL Server’a yazabilmesi
- NumPy ile cosine similarity hesaplamalarının kolay yapılabilmesi
- SQL Server dışındaki tüm işlemleri betik haline getirebilmesi
Ek: Kubernetes Üzerinde Azure Arc SQL Server ile Olsaydı Ne Olurdu?
Azure Arc ile Kubernetes ortamında çalışan bir SQL Server ortamında embedding süreci, yapılandırmaya bağlı olarak farklılık gösterir.
1. Eğer Arc destekli SQL Server örneğinde ‘AI_RUNTIME=ON’ yapılandırması etkinse ve model endpoint tanımı yapılabiliyorsa, embedding işlemi SQL içerisinde yapılabilir. Örneğin;
SELECT AI_GENERATE_EMBEDDINGS(‘nomic-embed-text’, ‘SQL Server embedding destekliyor mu?’);
Bu durumda Python veya dış araçlara ihtiyaç kalmaz.
2. Eğer AI desteği kapalıysa ya da kullanılan model Ollama gibi Azure dışı bir modelse, embedding üretimi yine dışarıdan yapılmalı (örneğin Python ile) ve SQL Server’a manuel olarak aktarılmalıdır.
Özetleyecek olursak eğer:
- AI destekli Arc SQL Server: Python opsiyonel
- AI desteksiz Arc SQL Server: Python zorunlu
- Azure OpenAI gibi resmi endpointler tanımlıysa tamamen SQL içinden embedding üretimi mümkündür.
Ek: Azure SQL Üzerinde Bu Senaryo Nasıl İşler?
Eğer bu senaryoyu local SQL Server 2025 yerine Azure SQL üzerinde çalıştırmak isterseniz, Python ihtiyacı yine ortamın yeteneklerine göre şekillenir:
- Azure SQL Database (PaaS): AI_RUNTIME veya AI_MODEL desteği bulunmaz. Embedding üretimi için Python veya başka dış servis gerekir.
- Azure SQL Managed Instance (MI): AI desteği henüz aktif değildir. Python kullanımı yine gereklidir.
- Azure Arc SQL Server (AI_RUNTIME=ON): Eğer model HTTP endpoint olarak tanımlanabiliyorsa Python ihtiyacı ortadan kalkar.
- Azure OpenAI + Azure Function + Azure SQL: Embedding üretimi dış servisle yapılabilir, veritabanına sonuç aktarılır.
Dolayısıyla şu an (Haziran 2025 itibariyle) embedding işlemini doğrudan Azure SQL içinden yapmak mümkün değildir. Bu nedenle Python, embedding üretimi ve similarity hesaplamaları için halen gereklidir. Ancak Microsoft’un ilerleyen sürümlerde AI_RUNTIME desteğini hem Azure SQL MI hem de SQL Server 2025 RTM sürümlerinde aktif hale getirmesi beklenmektedir.
🔔 Not: Bu içerik Haziran 2025 itibarıyla SQL Server 2025 Public Preview sürümüne göre hazırlanmıştır. Bu sürümde AI_RUNTIME ve AI_MODEL gibi özellikler aktif değildir. Bu nedenle, embedding işlemleri SQL Server içinde değil; Ollama ve Python aracılığıyla dışarıda yapılmıştır.
📌 Ek Bilgi: SQL Server 2025’in RTM sürümünde bu özelliklerin doğrudan desteklenmesi beklenmektedir. Bu nedenle bu döküman, geçerli Preview koşullarında bir workaround yaklaşımı olarak paylaşılmaktadır.