
Filtered Index, SQL Server 2008 ile gelen, optimize edilmiş bir nonclustered index’tir. Oluşturulurken kullanılan where anahtar kelimesi sayesinde index key’in bütün verilerini değil sadece alt kümesini içerir. İyi tanımlanmış bir Filtered Index performansı attırabildiği gibi bakım maliyetini düşürebilmekte ve diskte daha az yer kaplayabilir.
- Filtered Index Sorgu Performansını Arttırır : Filtered Index normal Index’e oranla daha az data içerdiği için bu Index üzerinden yapılacak seek/scan işlemleri normal Index üzerinden yapılacak seek/scan işlemlerine oranla daha performanslı çalışacaktır. Ayrıca Filtered Index için otomatik olarak oluşacak olan istatistik te veriyi daha iyi temsil edeceğinden estimated rows daha iyi tahmin edilecek, dolayısıyla da Index’e erişim metodu daha iyi belirlenebilecektir.
- Index Bakım Maliyetlerini Düşürür : Index fragmante olduğu zaman bakım yapılarak bu fragmantasyonun giderilmesi gerekir. (Detaylı bilgi için şu makaleyi inceleyebilirsiniz.) Index fragmantasyonu tabloda DML işlemleri olduğu zaman oluşur. Filtered Index normal NonClustered Index’e oranla daha az veri içerdiği için fragmante olma ihtimali daha azdır. Ayrıca fragmante olsa dahi bakım işlemi sırasında daha az data ile uğraşılacağı için bakım maliyeti her halukarda normal index’e oranla daha az olacaktır.
- Disk Maliyetini Düşürür : Daha önceki maddelerde de belirttiğim gibi Filtered Index datanın tamamını içermediği için normal Index’e oranla daha az yer kaplar.
Şimdi konu hakkında biraz örneklendirme yapalım.
TblPerson isimli bir tablonuz var . Bu tablo içerisinde Name ve SurName bilgisi mevcut. Siz SurNamebilgisine bağlı olarak arama yapıyorsunuz.
Bahsedilen işlem için ;
create table tblPerson (Name Varchar(10),Surname varchar(20))
Tablo içerisine örnek kayıt girdilerini yapıyoruz ( Bu işlem için anlamlı data olabilmesi adına Red-Gate Data Generator Kullandım) ve TblPerson isimli table kontrol ettiğimizde aşağıdaki gibi bir sonuç görüyoruz.
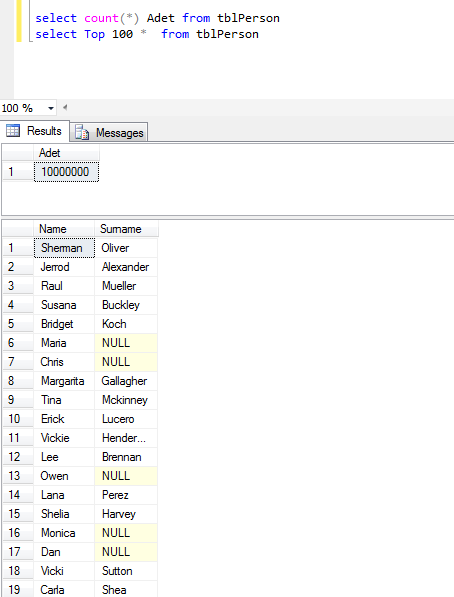
Şimdi TblPerson table üzerinde index tanımlamalarını yapıyoruz.
--Surname için normal bir NonClustered Index oluşturuyoruz create nonclustered index IX_RegularIndex on tblPerson (Surname) GO --Surname için Filtered NonClustered Index oluşturuyoruz create nonclustered index IX_FilterIndex on tblPerson (Surname) where Surname is not null GO
Index Tanımlarımızı da yaptık şimdi gerekli karşılaştırma işlemini gerçekleştirelim ;
SELECT i.index_id, i.name, i.type_desc, ps.reserved_page_count, ps.used_page_count,
ps.reserved_page_count*8 as Size_KB,
ps.row_count, i.filter_definition
FROM sys.dm_db_partition_stats ps
INNER JOIN sys.indexes i ON ps.object_id = i.object_id AND ps.index_id = i.index_id
WHERE ps.object_id = OBJECT_ID('tblPerson')
Ekran görüntüsü ;
![]()
Resimde de gördüğünüz üzere normal NonClustered Index 10.000.000 kayıttan oluşurken Filtered Index’te null olan kayıtlar bulundurulmadığı için 5.997.802 kayıttan oluşmakta. Bu yüzden normal index 20 MB’a yakınken Filtered Index 14 MB civarında boyutunda. Disk açısından maliyetin nasıl düşürüldüğünü görmüş olduk.
Filtered Index’in avantajlarından bir tanesi de performans demiştik. Şimdi onunla da alakalı bir örneklendirme yapalım.
SET STATISTICS IO ON --Normal NonClustered Index'i force ederek select * from tblPerson WITH (INDEX=IX_RegularIndex) where SurName='Alexander' --Filtered Index'i force ederek select top 10 * from tblPerson WITH (INDEX=IX_FilterIndex) where SurName='Alexander'
![]()
IO karşılaştırmasına baktığımızda normal Index sorguyu tamamlamak için 6095 IO yaparken Filtered Index aynı sorguyu 13 IO yaparak getirebilmektedir.
Bu konuyu da burada noktalıyorum. Bir sonraki makalede görüşmek üzere..