

T-SQL sorgularında yapılan gizli hatalar, SQL performance tuning çalışmalarınızı boşa çıkarabilir. Biliyor muydunuz? Veritabanı boyutları, yanlış yazılmış sorgular nedeniyle beklenmedik şekilde %300’e kadar büyüyebilir ve performansı ciddi şekilde etkileyebilir.
SELECT * ifadelerinin kullanımı, JOIN’lerin yanlış yapılandırılması ve indekslerin göz ardı edilmesi, SQL Server performance tuning sürecinde sıklıkla karşılaştığımız sorunlardır. Özellikle büyük tablolarda indekslerin ihmal edilmesi, sorguların önemli ölçüde yavaşlamasına neden olabilir. Ayrıca, LIKE ifadelerinde joker karakterlerin yanlış kullanımı, indekslerin kullanılmasını engelleyerek tam tablo taramaları ve yavaş sorgu performansına yol açabilir.
Bu makale, performans tuzaklarını tespit etmek ve optimize edilmiş SQL Server sorguları yazmak isteyen DBA ve geliştiriciler için hazırlanmıştır. T-SQL’in Microsoft SQL Server veritabanları için genişletilmiş bir SQL uygulaması olarak, doğru kullanılmadığında birçok performans sorununa yol açabilir. Örneğin, COUNT() fonksiyonu NULL değerleri göz ardı eder ve bu da yanlış sonuçlara yol açabilir. Benzer şekilde, örtük dönüşümler (implicit conversions), SQL Server’ın veri tiplerini karşılaştırma sırasında dönüştürmesine neden olarak optimal olmayan sorgu planlarına yol açabilir.
Kapsamlı bir SQL query performance tuning stratejisi, donanım, sunucu ayarları ve sorgu optimizasyonunu içermelidir. Bu makalede, gerçek dünya örnekleri ve pratik ipuçlarıyla desteklenmiş bir rehber sunarak, query tuning becerilerinizi bir üst seviyeye taşımanıza yardımcı olacağız.
Performans hatalarının neden genelde görünmez olduğu
“SQL hatalarının çoğu, sorguların, tabloların veya ilişkilerin yanlış yapılandırılmasından kaynaklanır ve bu hatalar sistem performansını beklenmedik şekilde düşürebilir.” — Çağlar Özenc, Microsoft Data Platform MVP
Performans sorunları genellikle hemen göze çarpmaz ve bu durum veritabanı yöneticilerinin SQL Server performans iyileştirme çalışmalarını zorlaştırır. Aslında, sorgu performans sorunları, özellikle küçük veri setleriyle çalışırken fark edilmeyebilir. Ancak veritabanı büyüdükçe ve daha fazla kullanıcı sistemi kullanmaya başladıkça, bu verimsizlikler birikerek ciddi performans sorunlarına dönüşür [[1]].
Kötü yazılmış sorgular genellikle aşamalı performans bozulmasına neden olur. Kullanıcılar zamanla giderek daha yavaş yanıt süreleri yaşarlar, bu da kullanıcı memnuniyetini ve üretkenliği doğrudan etkiler [1]. Başlangıçta sorunlu görünmeyen sorgular, veri hacmi arttıkça veya kullanıcı yükü yükseldiğinde gerçek sorunlar haline gelir.
Verimsiz sorgular, sistemde önemli miktarda kaynak tüketir:
- CPU kullanımında beklenmedik artışlar
- Bellek tüketiminde yükselme
- Disk I/O işlemlerinin artması
- Genel sistem kaynaklarında baskı oluşması [1]
Bu kaynakların aşırı kullanımı, diğer uygulamaların performansını da etkileyebilir ve operasyonel maliyetleri artırabilir. Ayrıca, kötü yazılmış sorgular gizli darboğazlar yaratarak ölçeklenebilirliği olumsuz etkiler [1].
Bazı performans sorunları uzun süre fark edilmez çünkü:
- Yedekleme, indeksleme veya veri taşıma gibi rutin bakım görevleri uzar
- Hata ayıklama ve sorun giderme süresi artar
- Kullanıcılar ara sıra yavaşlamalar yaşarlar ancak bunları sistematik bir sorun olarak raporlamazlar [1]
Öte yandan, SQL Server performans verilerini toplar, ancak bu veriler sadece bellekte tutulur ve sunucu yeniden başlatıldığında kaybolur [2]. Bu nedenle, sorgu performansıyla ilgili sorunlar tespit edilmeden önce uzun süreler geçebilir.
Kullanılmayan indeksler de performansı gizlice etkileyen faktörlerdendir. Birçok deneyimli veritabanı uzmanı, eksik indekslerin SQL Server performansını olumsuz etkilediğini bilir ancak kullanılmayan indekslerin de performansı olumsuz etkileyebileceğini gözden kaçırabilir. Bu indeksler her ekleme, güncelleme veya silme işlemi sırasında gereksiz kaynak tüketir [3].
Performans sorunlarını tespit etmenin ilk adımı, bu sorunların genellikle hemen ortaya çıkmadığını kabul etmektir. SQL query performance tuning çalışmaları yapılırken, sorguların küçük veri setlerinde hızlı çalışabileceği, ancak veri hacmi arttıkça performans sorunlarının ortaya çıkacağı unutulmamalıdır. Ayrıca, uygulama trafiği ve iş yükü hacmindeki artışlar da CPU kullanımını artırarak performans sorunlarına yol açabilir [4].
SQL Server performans iyileştirme çalışmalarının en zor kısmı, görünmeyen sorunları tespit etmek ve çözmektir. Bunun için sistematik bir yaklaşım ve SQL performans tuning adımlarını dikkatle uygulamak gerekir.
Sistem üzerindeki etkileri (CPU, IO, bekleme süreleri)
Kötü yazılmış SQL sorguları, sistem kaynaklarına ciddi yük bindirir ve veritabanı performansını doğrudan etkiler. Bu etkileri üç ana kategoride inceleyebiliriz: CPU kullanımı, disk I/O operasyonları ve bekleme süreleri.
CPU Üzerindeki Etkiler: Sorgu performans sorunlarının en yaygın nedenlerinden biri, tablo veya indeks taramalarına bağlı yüksek mantıksal okumalardır [5]. SQL Server’da,
Sqlservr.exe
işleminin CPU kullanımı %90’ın üzerine çıktığında, genellikle sorunun kaynağı verimsiz sorgulardır. Özellikle tablo veya indeks taramaları, sıralama işlemleri, hash operasyonları ve döngüler (nested loop veya WHILE) yüksek CPU tüketiminin başlıca nedenleridir [5]. Bu sorunları teşhis etmek için
sys.dm_exec_requests
DMV’sini kullanarak sorgular tarafından tüketilen CPU miktarını izleyebilirsiniz.
I/O Operasyonlarının Etkileri: I/O darboğazları genellikle tespit edilmesi en zor sorunlar arasındadır ve çoğunlukla bellek veya CPU sorunlarından kaynaklanır [6]. Microsoft’un deneyimlerine göre, bir I/O isteğinin 1 saniyeden fazla, hatta 15 saniyeye kadar sürdüğü durumlar olabilir [7]. I/O yanıt süreleri tutarlı bir şekilde 10-15 milisaniyeyi aştığında, I/O bir darboğaz olarak kabul edilir [7]. Bu gecikmeleri tespit etmek için
PAGEIOLATCH_*
,
WRITELOG
ve
ASYNC_IO_COMPLETION
gibi bekleme tiplerini ve
sys.dm_io_virtual_file_stats
DMV’sini kullanabilirsiniz.
Bekleme Sürelerinin Anlamı: SQL Server’da yükselen bekleme süreleri, sistem üzerindeki baskıyı gösteren önemli göstergelerdir. Bekleme istatistikleri şu durumları işaret edebilir:
- Disk gecikmesi: Sayfaların veri veya log dosyalarına yazılması bekleniyorsa
- Tempdb sorunları: Sorgular geçici tablolar kullanıyorsa veya sorgu planlarında tempdb dökülmeleri varsa
- Kaynak çakışması: Birden fazla işlem aynı kaynaklar için rekabet ediyorsa [8]
Bununla birlikte, performans sorunlarının tespiti için
sys.dm_db_wait_stats
DMV’sini kullanarak tüm bekleme tiplerinin bilgilerine erişebilir ve
sys.dm_os_waiting_tasks
ile hangi görevlerin kaynak beklediğini belirleyebilirsiniz [8].
Sonuç olarak, SQL Server performans iyileştirme çalışmalarında dikkat edilmesi gereken üç temel alan şunlardır: disk aktivitesi, işlemci kullanımı ve bellek kullanımı [9]. Bu alanları düzenli olarak izleyerek potansiyel darboğazları erkenden tespit edebilir ve SQL query performance tuning sürecinizi daha etkili hale getirebilirsiniz.
Gerçek dünya problem örneği (örn. kampanya döneminde çöken sistem)
Bir e-ticaret platformunun yıllık büyük kampanya döneminde yaşadığı sistematik çöküş, SQL Server performans sorunlarının gerçek dünyadaki etkilerini açıkça gösterir. Kullanıcı sayısının hızla artması sonucunda, normalde sorunsuz çalışan veritabanı sorgularının ciddi performans darboğazlarına dönüştüğü görülmüştür [10].
Örneğin, bir finansal kuruluş müşterilerine hizmet verme yeteneğini doğrudan etkileyen önemli bir veritabanı performans yavaşlaması yaşadı. IT ekibi, temel bankacılık işlemlerine ait özel bir sorgunun beklenenden çok daha uzun sürdüğünü tespit etti. SQL Server’ın Query Execution Plan özelliği kullanılarak yapılan incelemede, sorgunun büyük bir işlem tablosunda tam tablo taraması yaptığı belirlendi. Sorun, WHERE ifadesinde kullanılan sütunlara bir indeks eklenerek çözüldü ve sorgunun çalışma süresi önemli ölçüde düştü [11].
Benzer şekilde, bir çevrimiçi perakende şirketi, özellikle yoğun dönemlerde web sitesinin yavaşlamasına neden olan sorunlar yaşıyordu. SQL Server Performans İzleme araçları ile yapılan analizde, tempDB veritabanında latch çekişme sorunları olduğu ortaya çıktı. DBA ekibi, Microsoft’un önerdiği gibi tempDB’yi mantıksal çekirdek sayısına eşit sayıda veri dosyasına böldü ve bu çekişmeyi azaltarak tempDB kullanan operasyonların performansını artırdı [11].
E-ticaret platformlarında özellikle yoğun alışveriş saatlerinde yaşanan ağır performans sorunları genellikle istatistiklerin eskimesi nedeniyle ortaya çıkar. Güncel olmayan istatistikler, SQL Server’ın verimsiz sorgu yürütme planları oluşturmasına neden olur. Bu sorun, tablolar için istatistiklerin düzenli olarak güncellenmesi ve yoğun olmayan saatlerde çalışacak otomatik istatistik güncelleme işi oluşturularak çözülebilir [11].
Kampanya dönemlerinde sistem çökmelerinin bir diğer yaygın sebebi ise locking ve blocking sorunlarıdır. Bir sağlık kurumunun SQL Server veritabanında çalışan hasta yönetim sistemi, özellikle birden fazla kullanıcı eş zamanlı olarak hasta kayıtlarını güncellerken yavaş performans gösterdi. DBA ekibi sorunun kaynağının aşırı kilitleme olduğunu tespit etti. Bu durumda:
- SQL Server’da satır sürümlenmeye dayalı izolasyon seviyeleri (Snapshot veya Read Committed Snapshot Isolation) uygulandı
- İşlemleri mümkün olduğunca kısa tutacak şekilde uygulama kodu optimize edildi
- Böylece kilitlerin tutulma süresi azaltılarak sistem performansı önemli ölçüde iyileştirildi [11]
Kampanya dönemlerinde görülen SQL Server performans sorunlarını önlemek için deneyimlerden edinilen önemli derslerden biri, sorgu derlemeleri ve yeniden derlemelerin CPU kullanımını artırabileceğidir. Parametrize edilmemiş sorgular kullanıldığında SQL Server her sorgu için yeni bir plan derlemek zorunda kalır. Bunun yerine parametreli sorgular veya saklı prosedürler kullanılarak, SQL Server’ın mevcut yürütme planlarını yeniden kullanması sağlanabilir [11].
Kötü Yazılmış JOIN’ler
JOIN komutları, SQL Server sorgularının temel yapı taşlarından biridir ancak doğru kullanılmadığında performansı ciddi şekilde düşüren tuzaklar haline gelebilir. Veri tabanlarında tablolar arasındaki ilişkileri kuran bu komutlar, verimlilik açısından kritik öneme sahiptir.
JOIN’lerin kötü yazılması, veritabanı performansını beklenmedik şekilde etkileyebilir. Özellikle çok sayıda satır içeren tablolarda yanlış JOIN kullanımı, sorgu çalışma süresini saniyelerden dakikalara, hatta saatlere çıkarabilir. Bu durum, sistemin yanıt süresini uzatarak kullanıcı deneyimini olumsuz etkiler ve diğer işlemleri de yavaşlatır.
Kötü yazılmış JOIN’lerin en yaygın hatalarından bazıları şunlardır:
- Join şartının tamamen eksik olması (Cartesian product)
- Yanlış sütunlar üzerinden JOIN yapılması
- İndekslenmemiş sütunlar üzerinden JOIN gerçekleştirilmesi
- JOIN tipinin (INNER, LEFT, RIGHT) yanlış seçilmesi
Sorgu optimizasyonu sırasında, execution plan analizi JOIN performans sorunlarını tespit etmenin en etkili yöntemlerinden biridir. SQL Server Management Studio’daki execution plan, hangi JOIN operasyonunun en çok kaynağı tükettiğini görmenizi sağlar.
Cartesian Product Riski
Cartesian Product (çapraz çarpım), JOIN koşulu belirtilmediğinde oluşan ve veritabanı performansını en çok düşüren operasyonlardan biridir. Bu durumda, birinci tablodaki her satır ikinci tablodaki tüm satırlarla eşleştirilir ve sonuç kümesi orijinal tablo boyutlarının çarpımı kadar büyür.
Örneğin, 1.000 satırlık bir müşteri tablosu ile 10.000 satırlık bir sipariş tablosu arasında koşulsuz bir JOIN yapıldığında, sonuç 10 milyon satır içerecektir. Bu işlem, sadece işlemci yükünü artırmakla kalmaz, aynı zamanda büyük miktarda bellek tüketir ve disk I/O operasyonlarına neden olur.
Cartesian Product oluşumunu önlemek için:
- Her JOIN ifadesinde mutlaka bir ON koşulu belirtilmelidir
- Koşul, ilişkisel bütünlüğü sağlayan primary key ve foreign key sütunlarına dayanmalıdır
- JOIN öncesi ve sonrası satır sayısı kontrol edilmelidir
Bir SQL Server performans iyileştirme sürecinde, öncelikle Cartesian Product üreten sorgular tespit edilmeli ve düzeltilmelidir. Bu tür sorgular genellikle execution plan’da “Nested Loop” işlemleri olarak görünür ve çok yüksek “estimated row counts” değerleri taşır.
SQL Server profiler aracı kullanılarak, uzun süren sorguları izleyebilir ve JOIN performans sorunlarını tespit edebilirsiniz. Ayrıca, sys.dm_exec_query_stats DMV’si üzerinden en çok kaynak tüketen sorguları bularak kötü yazılmış JOIN’leri belirleyebilirsiniz.
Join şartlarının eksik bırakılması, büyük veri seti şişmesi
JOIN sorguları yazarken en sık yaşanan ve tehlikeli performans sorunlarından biri, JOIN şartlarının eksik bırakılmasıdır. Bu sorun, veritabanında “join explosion” (birleştirme patlaması) olarak da bilinen duruma yol açarak veritabanını aşırı yükler.
JOIN şartları eksik bırakıldığında, SQL Server iki tablodaki tüm satırları birbiriyle eşleştirmeye çalışır. Bu durum, matematiksel olarak bir Kartezyen çarpımına (Cartesian product) neden olur. Sonuç olarak, 1.000 satırlık bir tablo ile 10.000 satırlık başka bir tablo arasında şartsız bir JOIN yapıldığında, sonuç kümesi 10 milyon satıra ulaşır.
Özellikle eski SQL sözdizimini kullanan geliştiriciler bu hataya daha sık düşebilirler. ANSI olmayan sözdiziminde JOIN şartları WHERE yan tümcesinde görünür ve bu format, yanlışlıkla bir JOIN şartını silme olasılığını artırır. Microsoft SQL Server’da ANSI JOIN sözdizimini kullanmak, bu tür JOIN şartı eksikliklerinin oluşma riskini azaltır.
JOIN patlaması sorununun en temel belirtisi, sorgu çalışma süresinin dramatik şekilde uzamasıdır. Normalde saniyeler içinde tamamlanan sorgular, dakikalar hatta saatler sürebilir. SQL Server Management Studio’da execution plan incelendiğinde, genellikle yüksek sayıda satır içeren bir tablo spool işlemi görülür.
Bir müşteri için geliştirilen ve 11 dakikadan fazla süren bir sorguda, execution plan analizi sonucunda 628.000 satırın 7 milyar satırlık bir havuza dönüştüğü ve 112 GB veri ürettiği tespit edilmiştir. Sorunun kaynağı JOIN ifadesinde kullanılan OR koşuluydu. Bu karmaşık JOIN, iki ayrı JOIN işlemine UNION kullanılarak bölündüğünde, sorgunun çalışma süresi 11 dakikadan 200 milisaniyeye düşmüştür.
Ayrıca, büyük veri setlerinde şişmeyi önlemek için aşağıdaki yöntemler etkilidir:
- JOIN yapılan tablolardaki kardinaliteyi azaltmak (veri hacmini sınırlamak)
- JOIN edilen kolonlara uygun indeksler eklemek
- Daha küçük tabloları sorguda önce yerleştirmek
- Subqueries kullanarak JOIN işlemlerini kademeli yapmak
Bazı durumlarda, birden fazla tabloda gruplandırma yaparken “combinatorial explosion” (kombinatoryal patlama) problemi yaşanabilir. Bu sorun, bir tablodaki her satırın diğer tablolardaki birden fazla satırla eşleştiği durumlarda ortaya çıkar. SQL Server performans tuning sürecinde bu sorunu çözmek için alt sorgular (subqueries) kullanabilir ve GROUP BY işlemlerini ayrı ayrı gerçekleştirebilirsiniz.
Genellikle gözden kaçan bir diğer nokta da, LEFT JOIN kullanmanın gerekliliğidir. Eğer bir tablodaki tüm kayıtları korumak istiyorsanız, ancak INNER JOIN kullanırsanız, eşleşmeyen kayıtlar sonuç kümesinden çıkarılır ve veri kaybına neden olabilir. Doğru JOIN türünü seçmek, hem veri bütünlüğü hem de performans açısından kritiktir.
Yanlış JOIN Türü Seçimi
SQL sorgu performansını etkileyen faktörlerden biri de doğru JOIN türünü seçmektir. Yanlış JOIN türü kullanımı, hem gereksiz kaynak tüketimine hem de yanlış sonuçların üretilmesine neden olabilir. Bu sorun özellikle karmaşık sorgularda ve büyük veri tabanlarda daha belirgin hale gelir.
INNER, LEFT, RIGHT JOIN farklarının yanlış anlaşılması
JOIN türleri arasındaki en temel fark, eşleşmeyen kayıtların nasıl ele alındığıdır. INNER JOIN yalnızca her iki tabloda da eşleşen kayıtları döndürürken, LEFT JOIN sol tablodaki tüm kayıtları ve sağ tablodaki eşleşen kayıtları, RIGHT JOIN ise sağ tablodaki tüm kayıtları ve sol tablodaki eşleşen kayıtları döndürür.
Birçok geliştirici, INNER JOIN kullanarak veri kaybı yaşar çünkü eşleşmeyen kayıtlar sonuç kümesinden çıkarılır. Örneğin, sipariş vermemiş müşterileri görmek istiyorsanız LEFT JOIN kullanmalısınız; aksi takdirde bu müşteriler sonuçta görünmez.
RIGHT JOIN kullanımı daha az yaygındır ve genellikle LEFT JOIN ile tablolar yer değiştirerek aynı sonuç elde edilebilir. Ancak bazı geliştiriciler bu iki tür arasındaki farkı karıştırarak sorgu performansını olumsuz etkiler.
Eksik Index Üzerinden JOIN
JOIN işlemlerinde performans sorunlarının en yaygın nedenlerinden biri, birleştirilen sütunlar üzerinde indeks bulunmamasıdır. İndekssiz bir JOIN işlemi, SQL Server’ın tüm tabloyu taramasına neden olarak sorgu süresini önemli ölçüde artırır.
İndekslenmemiş bir sütun üzerinden yapılan birleştirme işlemlerinde SQL Server, genellikle Hash Match veya Nested Loop gibi maliyetli operasyonlar kullanır. Bu da CPU kullanımını ve bellek tüketimini artırır.
SQL Server Management Studio‘daki execution plan özelliği, eksik indeksleri tespit etmek için mükemmel bir araçtır. Plan içindeki “Missing Index” uyarıları, hangi JOIN sütunlarının indekslenmeye ihtiyaç duyduğunu gösterir.
Index olmayan kolonlarda yapılan birleşimlerin ağır yük yaratması
İndekslenmemiş kolonlarda JOIN yapıldığında, SQL Server her bir eşleşmeyi bulmak için doğrusal tarama yapmak zorunda kalır. Bu durum, tablolar büyüdükçe üstel olarak artan bir performans sorunu yaratır.
Örneğin, her biri 100.000 satır içeren iki tablo arasında indekssiz bir JOIN yaptığınızda, SQL Server’ın teorik olarak 10 milyar karşılaştırma yapması gerekebilir. Bu işlem, disk I/O operasyonlarını artırır ve sorgu süresini dramatik şekilde uzatır.
Ayrıca indekslenmemiş JOIN’ler, tempdb üzerinde fazladan yük oluşturarak diğer sorguların performansını da etkiler. Hash tabloları genellikle tempdb’de oluşturulur ve büyük veri setleri için önemli disk alanı gerektirir.
Bu sorunları önlemek için:
- JOIN yapılan tüm sütunlara uygun indeksler ekleyin
- Sorgu planlarını düzenli olarak analiz edin
- İndeks önerilerini değerlendirin ve gereksiz indeksleri temizleyin
- İndeks bakımını düzenli olarak gerçekleştirin
Sonuç olarak, doğru JOIN türü seçimi ve indeksleme stratejisi, SQL Server performans iyileştirme çalışmalarının temel taşlarından biridir.
Gereksiz DISTINCT Kullanımı
DISTINCT anahtar kelimesi, SQL sorgularında sıklıkla kullanılan ancak genellikle gereksiz yere performans maliyeti yaratan bir özelliktir. Birçok geliştirici, sorgu sonuçlarında oluşan tekrarları kaldırmak için DISTINCT kullanmaya başvurur. Ancak bu tekrarların varlığı, çoğu zaman zayıf veritabanı tasarımının veya verimsiz sorguların bir göstergisidir [12].
DISTINCT vs. GROUP BY
DISTINCT ve GROUP BY arasındaki temel benzerlik, her ikisinin de tekrarlanan değerleri filtreleme yeteneğidir. SQL Server’da DISTINCT içeren ve SQE kullanılarak çalıştırılan tüm sorgular, arka planda GROUP BY kullanacak şekilde yeniden yazılır [13]. Bu nedenle, aşağıdaki iki sorgu aslında aynı execution plan‘e sahiptir:
-- DISTINCT kullanımı
SELECT DISTINCT c1, c2, c3 FROM t1 WHERE c1 > const;
-- GROUP BY kullanımı
SELECT c1, c2, c3 FROM t1 WHERE c1 > const GROUP BY c1, c2, c3;
Execution plan açısından bakıldığında, bu iki yaklaşım arasında genellikle performans farkı yoktur. Her iki sorgu da aynı plan operatörlerini ve sıralamayı kullanır, operatör maliyetleri ve sorgu maliyetleri aynıdır [14].
Hangisinin ne zaman kullanılacağı, yanlış kullanım örnekleri
En yaygın hatalı DISTINCT kullanımlarından biri, sorgu JOIN’lerinin yanlış yapılandırılması sonucu oluşan duplikasyonları gizlemek için kullanılmasıdır. Bu, asıl sorunu çözmek yerine sadece belirtilerini maskeler. Özellikle yüksek hacimli tablolarda bu yaklaşım, performansı önemli ölçüde düşürür [15].
DISTINCT kullanmak yerine:
- JOIN koşullarını doğru şekilde belirleyin
- Uygun indeksler ekleyin
- Gerekiyorsa tablo yapısını normalize edin
Bununla birlikte, bazı durumlarda DISTINCT kullanmak kaçınılmazdır. Özellikle uygulama mantığı gereği benzersiz değerler gerektiğinde, DISTINCT kullanımı anlamlıdır. Ancak her zaman ilk seçenek olmamalıdır [14].
DISTINCT’in Execution Plan’e Etkisi
SQL Server’da DISTINCT kullanıldığında, execution plan’e genellikle ek bir Sort operatörü eklenir. Bu operatör, sonuç kümesindeki tekrarlanan değerleri kaldırmak için kullanılır ve sorgu maliyetinin büyük bir kısmını oluşturur.
Gerçek bir örnekte, DISTINCT olmadan bir sorgunun tahmini toplam maliyeti 0.438585 iken, DISTINCT eklendiğinde bu maliyet 1.75954’e yükseldi. Bu, yaklaşık 4 kat artış anlamına gelir [12].
Fazladan sorting, hashing ve cost artışı
DISTINCT kullanımı, CPU süresini de önemli ölçüde artırır. DISTINCT olmayan sorguda CPU süresi 15 ms iken, DISTINCT eklendiğinde bu süre 78 ms’ye çıktı [12]. Bu artış, büyük veri setlerinde daha da belirgin hale gelir.
Ayrıca, DISTINCT ile LIMIT birleştirildiğinde performans daha da kötüleşebilir. Veritabanı motoru, LIMIT satırlarını getirmeden önce tüm benzersiz satırları bulmak zorunda kalır, bu da özellikle büyük tablolarda sorgu süresini önemli ölçüde uzatır [16].
Sonuç olarak, DISTINCT kullanırken daima bilinçli bir karar vermek ve alternatif yaklaşımları değerlendirmek gerekir. SQL Server performans iyileştirme çalışmalarında, gereksiz DISTINCT kullanımlarını tespit etmek ve optimize etmek, sorgu performansını artırmanın etkili yollarından biridir.
Aşırı Temp Table ve Table Variable Kullanımı
Geçici tablolar ve değişken tablolar, karmaşık SQL sorgularında sık kullanılan araçlardır. Ancak aşırı kullanıldıklarında, veritabanı performansını önemli ölçüde düşürebilirler. Bu yapılar, basit görünseler de, tempdb üzerinde beklenmedik yüklere ve sistem genelinde darboğazlara neden olabilir.
Tempdb Üzerindeki IO Yükü
Temp tablolar ve tablo değişkenleri, SQL Server’da tempdb veritabanında saklanır. Tempdb, tüm oturumlar ve uygulamalar tarafından paylaşılan ortak bir kaynaktır. Aşırı sayıda geçici tablo oluşturulduğunda veya büyük veri setleriyle çalışıldığında, tempdb üzerindeki disk I/O operasyonları hızla artabilir. Bu durum, tüm sistem performansını etkileyebilir çünkü tempdb, SQL Server’ın tüm geçici işlemleri için paylaşımlı bir kaynaktır.
Geçici tablolar ve tablo değişkenleri arasında önemli farklar vardır:
| Özellik | Temp Table (#table) | Table Variable (@table) |
|---|---|---|
| İstatistikler | Tutulur | Tutulmaz |
| İndeksler | Desteklenir | Sadece primary key/unique |
| Tahmini Satır Sayısı | Gerçeğe yakın | Her zaman 1 satır |
| Transaction Log | Loglanır | Daha az log etkisi |
Temp table’ın tempdb üzerindeki etkisi ve darboğaz yaratması
Temp table’lar tempdb’de depolandığından, yoğun kullanımları çeşitli performans sorunlarına yol açabilir. Bunlar arasında:
- Tempdb’nin disk alanının hızla dolması
- Latch çekişmelerinin artması
- Aşırı log üretimi ve log büyümesi
- Gereksiz sayfa ayırma ve dealokasyon işlemleri
Özellikle yüksek eşzamanlı sistemlerde, her kullanıcı isteği için yeni temp tablolar oluşturulması, tempdb üzerinde ciddi bir yük oluşturur. Bu yük, sistemdeki tüm sorguların genel performansını etkileyebilir.
CTE veya Derived Table Alternatifleri
Temp tablolara alternatif olarak, Common Table Expressions (CTE) veya derived table’lar (türetilmiş tablolar) kullanabilirsiniz. Bu yapılar genellikle daha az kaynak tüketir ve yürütme planları daha verimli olabilir:
-- CTE Örneği
WITH SatisOzeti AS (
SELECT UrunID, SUM(Miktar) as ToplamSatis
FROM Satislar
GROUP BY UrunID
)
SELECT u.UrunAdi, s.ToplamSatis
FROM SatisOzeti s
JOIN Urunler u ON s.UrunID = u.ID;
Daha hafif, performans dostu çözümler
Geçici tablolarla ilgili performans sorunlarını azaltmak için izleyebileceğiniz bazı stratejiler şunlardır:
- Sadece gerektiğinde temp table kullanın
- İhtiyaç duyulan en az veriyi saklayın
- Küçük veri setleri için tablo değişkenleri tercih edin
- CTE veya türetilmiş tablolar gibi alternatifler kullanın
- Temp table’ları işiniz bitince hemen bırakın (DROP)
Ayrıca, tempdb’nin yapılandırılması da performans üzerinde büyük etkiye sahiptir. Tempdb’yi çoklu veri dosyalarına ayırmak, ayrı bir disk üzerine yerleştirmek ve düzenli olarak izlemek, performans sorunlarını önlemek için önemli adımlardır.
Sonuç olarak, temp table ve tablo değişkenlerinin kullanımı kaçınılmaz olabilir, fakat bilinçli kullanım ve düzenli izleme ile SQL Server performans iyileştirme çalışmalarınızda önemli kazanımlar elde edebilirsiniz.
Yanlış veya Fazla Index Kullanımı
İndeksler, SQL Server’da sorgu performansını artırmak için vazgeçilmez yapılardır, ancak yanlış kullanıldıklarında veya sayıca fazla olduklarında, beklenenin aksine performans düşüşlerine neden olabilirler. Veritabanlarını optimize etmeye çalışırken, bazı geliştiriciler “daha fazla indeks daha iyi performans” varsayımıyla hareket eder, fakat bu yaklaşım genellikle ters etki yaratır.
Index Overdose ve Performans Kaybı
İndeksler sorguları hızlandırırken, aynı zamanda bakım maliyeti de getirir. Her yeni indeks, veritabanı motorunun sorgu planı oluşturma sürecinde değerlendirmesi gereken bir seçenek daha demektir. Çok sayıda indeks, optimizasyon süresini uzatarak sorgu performansını olumsuz etkiler. Ayrıca, fazla indeksler SQL Server’ın bellek kullanımını artırır ve daha fazla veri sayfasının önbelleğe alınmasına engel olur.
Fazla index’in DML (insert/update/delete) yükünü artırması
İndeksler okuma performansını iyileştirir, ancak veri değişikliği işlemlerini yavaşlatır. Her DML işlemi, tablodaki tüm indekslerin güncellenmesini gerektirir. Örneğin, 10 indeksi olan bir tabloya yapılan bir INSERT işlemi, indekssiz duruma göre 10 kat daha fazla disk yazma işlemi gerektirebilir. Bu durum, özellikle yoğun veri yazma işlemleri yapan sistemlerde ciddi performans sorunlarına yol açar.
Kullanılmayan Index’leri Tespit Etme
SQL Server’da kullanılmayan indeksleri tespit etmek için Dynamic Management Views (DMV) kullanabiliriz. Bu DMV’ler, indekslerin kullanım istatistiklerini takip eder.
DMV kullanarak kullanılmayan index’leri bulma yöntemleri
Aşağıdaki sorgu, kullanılmayan indeksleri bulmak için kullanılabilir:
SELECT OBJECT_NAME(i.object_id) AS TableName,
i.name AS IndexName,
i.index_id AS IndexID,
dm_ius.user_seeks + dm_ius.user_scans + dm_ius.user_lookups AS TotalUses
FROM sys.indexes AS i
LEFT JOIN sys.dm_db_index_usage_stats AS dm_ius
ON i.object_id = dm_ius.object_id AND i.index_id = dm_ius.index_id
WHERE OBJECTPROPERTY(i.object_id, 'IsUserTable') = 1
AND dm_ius.user_seeks + dm_ius.user_scans + dm_ius.user_lookups = 0
ORDER BY OBJECT_NAME(i.object_id), i.index_id;
Eksik Index Senaryoları
Eksik indeksler, sorgu performansını önemli ölçüde düşürebilir. Eksik indeks genellikle WHERE, JOIN veya ORDER BY ifadelerinde kullanılan ancak indekslenmeyen kolonlarda ortaya çıkar.
Execution plan’den gelen index önerilerini doğru değerlendirme
SQL Server, execution plan içinde eksik indeks önerileri sunar. Ancak bu önerileri doğrudan uygulamak yerine, iş yükünüzü bütünsel olarak değerlendirmelisiniz. Bazen önerilen indeks başka sorguları yavaşlatabilir veya zaten benzer bir indeks mevcut olabilir.
Parametre Sniffing Problemi
Parametreli sorgular, SQL Server’da performans iyileştirme çalışmalarında sıklıkla gözden kaçan bir sorun kaynağıdır. Veri tabanı sunucusu, sorgu içindeki parametrelerin değerlerine göre alacağı aksiyon planını belirler ve bu süreçte bazı kritik hatalar ortaya çıkabilir.
Problemin Tanımı
Parametre sniffing, SQL Server’ın saklı prosedür veya parametreli sorgu ilk çalıştırıldığında, geçirilen parametre değerlerine göre bir yürütme planı oluşturması ve bu planı önbelleğe almasıdır. Bu davranış, genellikle verimli bir özelliktir fakat veri dağılımında dengesizlik olduğunda ciddi performans sorunlarına yol açar. Özellikle bir parametre değeri çok az satır döndürürken, başka bir değer milyonlarca satır döndürebiliyorsa, önceden oluşturulan plan yeni parametreler için uygun olmayabilir.
Plan cache, sniffing’in neden olduğu plansal problemler
SQL Server’da önbelleğe alınan planlar, belirli parametre değerlerine göre optimize edilmiştir. Bu, veri dağılımı değişken olduğunda problemler yaratır. Örneğin, bir ülke parametresi alan sorguda “Etiyopya” için oluşturulan plan, indeks tarama kullanabilirken, “Kosta Rika” için tüm tablo taraması gerekebilir. Aynı planın her iki durum için de kullanılması, beklenmedik performans düşüşlerine neden olur.
Çözüm Yöntemleri
Parametre sniffing sorunlarını çözmek için çeşitli yaklaşımlar mevcuttur:
- Yerel değişkenlerin kullanımı
- Sorguyu yeniden derleme (recompile)
- Optimize ipuçları (query hints)
- Koşullu mantık (IF/ELSE) kullanımı
- SQL Server 2022 ile gelen Parametre Duyarlı Plan (PSP) optimizasyonu
OPTIMIZE FOR, RECOMPILE, OPTION (RECOMPILE) gibi çözümler
WITH RECOMPILE
seçeneği, saklı prosedürlerde her çalıştırmada yeni bir plan oluşturur, ancak yüksek CPU kullanımına neden olabilir. Daha iyi bir yaklaşım,
OPTION (RECOMPILE)
ipucunu sadece problematik sorgulara uygulamaktır. Böylece yalnızca ihtiyaç duyulan sorgular için yeni planlar oluşturulur.
OPTIMIZE FOR (@parametre = değer)
kullanarak belirli bir parametre değeri için optimizasyon yapabilirsiniz. Alternatif olarak,
OPTIMIZE FOR UNKNOWN
ile SQL Server’ın ortalama değerlere göre plan oluşturmasını sağlayabilirsiniz. Bununla birlikte, bu yaklaşım her zaman optimal olmayan bir plan üretebilir.
Sorgu derleme ve yeniden derleme işlemleri CPU yoğun olduğundan, çözüm seçerken sistem yükünü ve sorgunun çalışma sıklığını göz önünde bulundurmanız gerekir.
Blocking ve Deadlock Problemleri
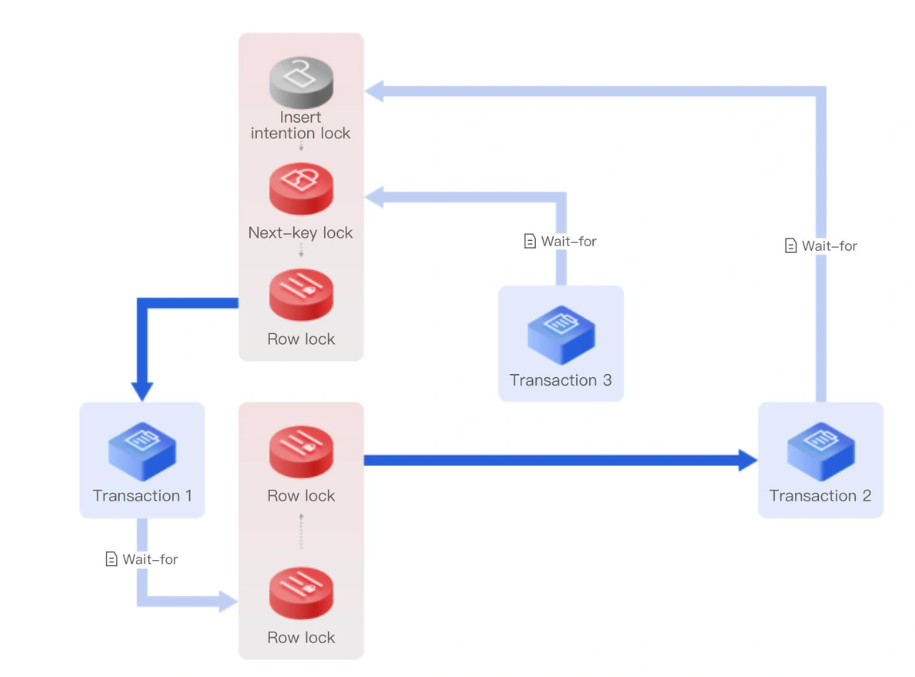
Image Source: Tencent Cloud
Veritabanlarında işlem güvenliği için kritik öneme sahip kilit mekanizmaları, performans sorunlarının ana nedenlerinden biri olabilir. Her veritabanı yöneticisinin mutlaka anlaması gereken iki sorun vardır: blocking ve deadlock.
Blocking vs. Deadlock Farkı
Blocking, bir işlemin başka bir işlem tarafından tutulan kaynağı beklemesi durumudur. Bu bekleme doğal bir durumdur ve genellikle birinci işlem tamamlandığında kendiliğinden çözülür. Ancak deadlock, iki veya daha fazla işlemin birbirlerinin tuttuğu kaynakları bekleyerek oluşan çıkmaz durumudur. SQL Server, deadlock durumlarında kurban seçerek (genellikle daha az kaynak tüketen işlem) sorunu çözer ve 1205 numaralı hata mesajını döndürür [1].
Basit bekleme ile karşılıklı kilitlenme farkı
Basit bekleme durumunda işlemler doğrusal bir sırada bekler ve sonunda kaynak serbest bırakıldığında devam eder. Öte yandan deadlock, döngüsel bir bağımlılık oluşturur. Örneğin: İşlem A, Kaynak 1’i kilitler ve Kaynak 2’yi bekler; İşlem B, Kaynak 2’yi kilitler ve Kaynak 1’i bekler. Bu durumda hiçbir işlem ilerleyemez [1].
Tespit ve Analiz Yöntemleri
SQL Server’da blocking ve deadlock problemlerini tespit etmek için şu araçları kullanabilirsiniz:
- System_health oturumu: Varsayılan olarak tüm deadlock olaylarını XML formatında kaydeder [17]
- Extended Events: Özel deadlock izleme oturumları oluşturabilirsiniz [18]
- Deadlock graph: Deadlock’a neden olan işlemleri görsel olarak gösterir [19]
- sys.dm_exec_requests ve sys.dm_os_waiting_tasks: Mevcut blocking durumlarını tespit eder [20]
Çözüm Stratejileri
Blocking ve deadlock sorunlarını azaltmak için etkili yöntemler:
- İşlemleri kısa tutun: Uzun süren işlemler blocking olasılığını artırır [1]
- DEADLOCK_PRIORITY kullanın: Hangi işlemin kurban seçileceğini belirlemek için [17]
- Row versioning kullanın: READ_COMMITTED_SNAPSHOT veya SNAPSHOT izolasyon seviyelerini etkinleştirin [1]
- LOCK_TIMEOUT ayarlayın: Beklemeler için maksimum süre belirleyin [1]
- Try-catch blokları ile deadlock tekrar denemeleri yapın: Deadlock kurbanı olduğunda işlemi otomatik tekrarlayın [17]
Doğru transaction yönetimi ve lock stratejisi, SQL Server performans iyileştirme çalışmalarının en önemli adımlarından biridir.
Execution Plan ve Query Cost Analizi
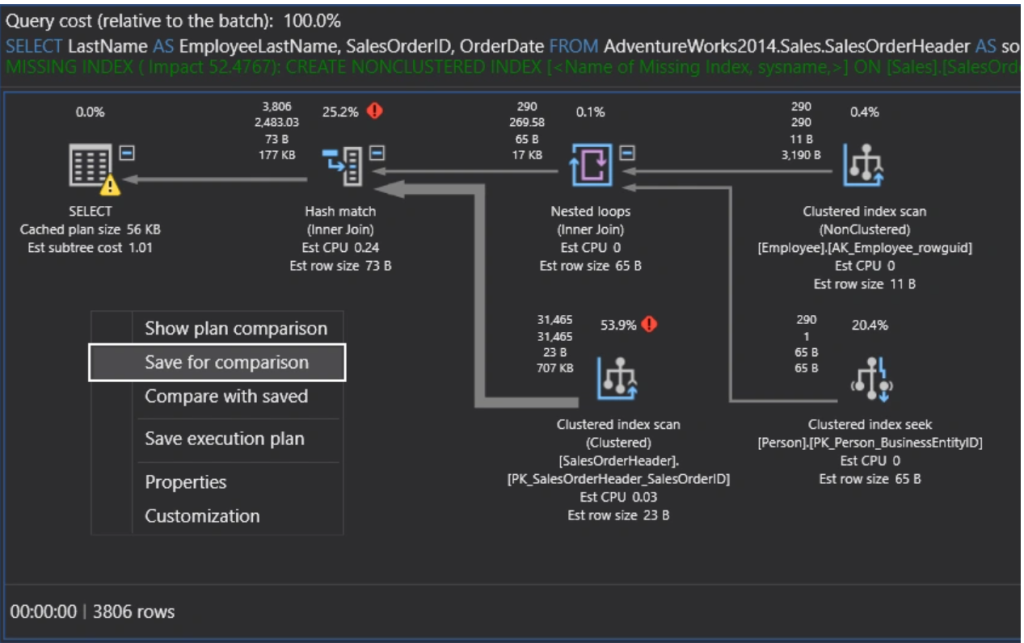
Image Source: Solution center – ApexSQL
“Çok sayıda mantıksal okuma (veya yazma) işlemine neden olan sorguları bulun ve uygun dizinleri kullanan disk G/Ç’sini en aza indirmek için bu sorguları ayarlayın.” — Microsoft, Technology Corporation and SQL Server Developer
SQL Server sorgu performansını iyileştirmenin en etkili yollarından biri Execution Plan (Yürütme Planı) analizidir. Bu planlar, veritabanı motorunun sorguları nasıl işlediğini gösteren değerli araçlardır.
Execution Plan Okuma Rehberi
Execution planlar sağdan sola ve yukarıdan aşağıya doğru okunur. Plan içindeki okların kalınlığı, operatörler arasında aktarılan veri miktarını gösterir. Kalın oklar, büyük veri kümelerinin taşındığını ve potansiyel performans sorunlarının olabileceğini işaret eder.
Her operatörün altında görünen yüzde değeri, o işlemin toplam sorgu maliyeti içindeki payını gösterir. Ayrıca, operatörlerin üzerine fare ile geldiğinizde, giriş/çıkış ve CPU maliyetleri gibi ayrıntılı bilgileri içeren bir araç ipucu görüntülenir.
Execution Plan’in En Pahalı Operator’lerinin Tespiti
En maliyetli operatörleri bulmak, performans iyileştirme çalışmalarının ilk adımıdır. SQL Server Management Studio’da bunları tespit etmek için planı incelerken en yüksek yüzdeye sahip operatörlere odaklanmalısınız. Karmaşık planlarda, “Find Node” özelliğini kullanarak belirli bir operatörü hızlıca bulabilirsiniz.
Operatörün gerçekten maliyetli olup olmadığını anlamak için, tahmini ve gerçek satır sayılarını karşılaştırın. Önemli farklılıklar, güncel olmayan istatistiklere işaret edebilir ve sorgu performansını olumsuz etkileyebilir.
Yük Yaratan Bölgeleri Bulmak
Execution plan’de yük yaratan bölgeleri tespit etmek için:
- En yüksek “subtree cost” değerine sahip operatörleri inceleyin
- Kalın okları takip edin – bunlar genellikle darboğaz bölgelerini gösterir
- “Ordered” özelliği “False” olan operatörleri kontrol edin – ek sıralama işlemleri gerektirebilir
Scan vs. Seek, Nested Loop vs. Hash Match Karşılaştırması
| Operatör | Kullanım Senaryosu | Performans Etkisi |
|---|---|---|
| Index Seek | Az sayıda satır gerektiğinde | Verimli, tercih edilir |
| Table/Index Scan | Tablo küçükse veya birçok satır gerekiyorsa | Büyük tablolarda maliyetli |
| Nested Loop | Az sayıda satır üzerinde birleştirme | Küçük veri setlerinde iyi |
| Hash Match | Büyük veri setlerinde birleştirme | Daha fazla bellek kullanır |
Sonuç olarak, execution plan analizi, SQL Server performans iyileştirme sürecinin en önemli adımlarından biridir. Özellikle büyük ve karmaşık sorgularda, problemli alanları tespit etmenizi ve kaynak kullanımını optimize etmenizi sağlar.
Sonuç ve Kapanış
SQL Server sorgu performansını iyileştirmek, görünmeyen tuzakları tespit etmek ve çözmek için sistematik bir yaklaşım gerektirir. Makale boyunca incelediğimiz performans sorunları, veritabanı sistemlerinin derinliklerinde gizlenen ve genellikle fark edilmesi zor olan problemlerdir. Özellikle JOIN operasyonlarının yanlış yapılandırılması, gereksiz DISTINCT kullanımı ve indeks stratejilerindeki hatalar, sorgu performansını dramatik şekilde düşürebilir.
Sorguların optimize edilmesi sürecinde, temp table kullanımının tempdb üzerindeki etkilerini ve parametre sniffing problemlerinin plan cache üzerindeki sonuçlarını göz ardı etmemek gerekir. Bunlar, sorgular küçük veri setlerinde test edilirken fark edilmeyen ancak üretim ortamında ciddi darboğazlara dönüşen faktörlerdir.
Blocking ve deadlock sorunları da veritabanı performansını etkileyen önemli unsurlar arasındadır. Bu sorunları doğru şekilde teşhis etmek ve çözmek için execution plan analizini etkin bir şekilde kullanmak şarttır. Execution planlar, sorguların nasıl çalıştığını göstererek, en maliyetli operatörleri ve optimizasyon fırsatlarını belirlemenizi sağlar.
Unutulmamalıdır ki, performans iyileştirme bir kerelik değil, sürekli yapılması gereken bir çalışmadır. Çünkü veritabanları büyüdükçe ve kullanım yoğunlaştıkça, daha önce sorun yaratmayan sorgular bile performans sorunlarına yol açabilir. Bu nedenle düzenli olarak sorguları izlemek, analiz etmek ve gerektiğinde optimize etmek önemlidir.
SQL Server’da performans sorunlarını çözmek için öncelikle sorunun kaynağını doğru tespit etmek gerekir. Ardından, uygun indeksleme stratejileri, etkili JOIN kullanımı ve gereksiz operasyonlardan kaçınma gibi tekniklerle sorguları optimize edebilirsiniz. Takımınızda sorgu performansını iyileştirmek ya da detaylı danışmanlık almak için bizimle iletişime geçin — birlikte çözümler üretelim!
Sonuç olarak, SQL Server performans katillerini tanımak ve onlarla etkili bir şekilde mücadele etmek, veritabanı sistemlerinizin sağlıklı ve verimli çalışmasını sağlamanın anahtarıdır. Bu makalede paylaştığımız bilgi ve teknikler, veritabanı performans sorunlarını tespit etmenize ve çözmenize yardımcı olacak değerli araçlardır. Bu araçları kullanarak, veritabanı sistemlerinizin performansını en üst düzeye çıkarabilir ve kullanıcı deneyimini önemli ölçüde iyileştirebilirsiniz.
En Kritik 3 Tuzak
SQL Server veritabanlarında performans sorunları derin bir bakış açısıyla ele alındığında, belirli tuzakların diğerlerinden daha tehlikeli olduğunu görebiliriz. Tecrübelerime dayanarak, en fazla sistem kaynağı tüketen ve çözümü en acil olan üç kritik performans katilini sizlerle paylaşmak istiyorum.
En sık yapılan hataların kısa özeti
1. İndeks Stratejisi Hataları: Birçok veritabanı uzmanına göre, indeksleme hataları en yaygın performans sorunlarından biridir. Buna hem eksik indeksler hem de aşırı indeksleme dahildir. Veritabanı geliştiricileri genellikle “daha fazla indeks = daha iyi performans” yanılgısına düşerler. Oysa fazla indeks, veri değiştirme (DML) operasyonlarını önemli ölçüde yavaşlatır. Her yeni indeks, sorgu planı oluşturma sürecinde değerlendirilmesi gereken ek bir seçenek anlamına gelir.
2. JOIN Şartlarının Eksik veya Yanlış Oluşturulması: JOIN operasyonları, doğru yapılandırılmadığında veritabanı performansını çökerten “join explosion” durumlarına yol açabilir. JOIN şartları eksik bırakıldığında, sonuç kümesinde tablo boyutlarının çarpımı kadar satır oluşur ve bu durum işlemci, bellek ve I/O kaynaklarının aşırı kullanımına neden olur.
3. Row-By-Row (RBAR) İşlemler: Geliştiricilerin set-tabanlı SQL operasyonları yerine satır-satır işlemler yapması (cursors veya WHILE döngüleri kullanması), SQL Server’da “RBAR” olarak bilinen büyük bir performans sorunudur. Bu yaklaşım, özellikle büyük tablolarda, sorgu süresini önemli ölçüde uzatır.
Okuyucuya Çağrı
Sorgularınızda bu tuzakları tespit ettiniz mi? Şimdi production ortamınızdaki sorguları gözden geçirin ve bu üç kritik hatanın izlerini arayın. Özellikle yavaş çalışan veya kaynak tüketen sorgularda, muhtemelen bu sorunlardan en az biriyle karşılaşacaksınız.
Sorunları çözmek için öncelikle execution plan analizi yaparak en maliyetli operatörleri belirleyin. İndeks kullanımını optimize edin, JOIN koşullarını gözden geçirin ve satır-satır işlemlerinizi set-tabanlı yaklaşımlara dönüştürün. Bu üç adım bile sorgu performansınızda dramatik iyileşmeler sağlayabilir.
Deneyim paylaşmaya, yorum yapmaya, soru göndermeye davet
Her veritabanı ortamı benzersizdir. Belki siz de projelerinizde bu tuzaklarla karşılaştınız? Veya belki de burada bahsetmediğimiz başka performans katilleri tespit ettiniz? Deneyimlerinizi yorumlarda paylaşın, sorularınızı gönderin. Birlikte öğrenmek ve SQL Server performans iyileştirme tekniklerimizi geliştirmek için bu makaleyi bir başlangıç noktası olarak kullanabiliriz.
Ayrıca, özel senaryolarınız için danışmanlık hizmeti almak veya ekibinizle birlikte SQL query performance tuning çalıştayı düzenlemek isterseniz, iletişim formumuz üzerinden bize ulaşın. Veritabanı performans sorunlarıyla birlikte mücadele edelim!
Referanslar
[1] – https://learn.microsoft.com/en-us/sql/relational-databases/sql-server-deadlocks-guide?view=sql-server-ver16
[2] – https://learn.microsoft.com/en-us/archive/msdn-magazine/2008/january/sql-server-uncover-hidden-data-to-optimize-application-performance
[3] – https://www.sqlservercentral.com/blogs/hidden-killers-of-sql-server-performance
[4] – https://docs.azure.cn/en-us/azure-sql/database/identify-query-performance-issues
[5] – https://learn.microsoft.com/en-us/troubleshoot/sql/database-engine/performance/troubleshoot-high-cpu-usage-issues
[6] – https://www.sqlshack.com/sql-server-monitoring-tools-for-disk-i-o-performance/
[7] – https://learn.microsoft.com/en-us/troubleshoot/sql/database-engine/performance/troubleshoot-sql-io-performance
[8] – https://learn.microsoft.com/en-us/azure/azure-sql/database/identify-query-performance-issues?view=azuresql
[9] – https://learn.microsoft.com/en-us/sql/relational-databases/performance-monitor/monitor-resource-usage-system-monitor?view=sql-server-ver16
[10] – https://medium.com/womenintechnology/reducing-load-on-sql-server-database-practical-strategies-for-enhanced-performance-9ae9fcd2680f
[11] – https://sqldbaschool.com/course/sql-server-performance-tuning/lessons/case-studies-and-real-world-scenarios/
[12] – https://www.sqlservercentral.com/blogs/the-effects-of-distinct-in-a-sql-query
[13] – https://www.ibm.com/docs/en/i/7.3?topic=overview-distinct-optimization
[14] – https://codingsight.com/is-sql-distinct-good-for-removing-duplicates-in-results/
[15] – https://www.linkedin.com/pulse/hidden-costs-using-select-distinct-unnecessarily-james-shelley
[16] – https://dba.stackexchange.com/questions/332435/distinct-with-limit-performance
[17] – https://www.site24x7.com/learn/resolve-sql-server-deadlocks.html
[18] – https://www.sqlshack.com/how-to-resolve-deadlocks-in-sql-server/
[19] – https://learn.microsoft.com/en-us/sql/tools/sql-server-profiler/analyze-deadlocks-with-sql-server-profiler?view=sql-server-ver16
[20] – https://www.mssqltips.com/sqlservertip/2429/how-to-identify-blocking-in-sql-server/